Using the most unhinged AVX-512 instruction to make the fastest phrase search algo
Disclaimers before we start
- For those who don’t want to read/don’t care that much, here are the results. I hope after seeing them you are compelled to read. TL;DR: I wrote a super fast phrase search algorithm using AVX-512 and achieved wins up to 1600x the performance of Meilisearch.
- The source code can be found here, and here is the crate.
- The contents of this blog post are inspired by the wonderful idea of Doug Turnbull from the series of blog posts about Roaringish. Here we will take these ideas to an extreme, from smart algorithms to raw performance optimization.
- I highly recommend reading the Roaringish blog post, but if you don’t want to, there will be a recap on how it works.
- This project has been almost 7 months in the making, with thousands and thousands of lines of code written and rewritten, so bear with me if I sound crazy. At the moment of writing, there are almost 2.7k LOC, but I have committed around 17k LOC (let’s take a few thousand because of
.lockfiles) (probably at the time of publishing this number has increased), so the project has been rewritten almost 6 times.
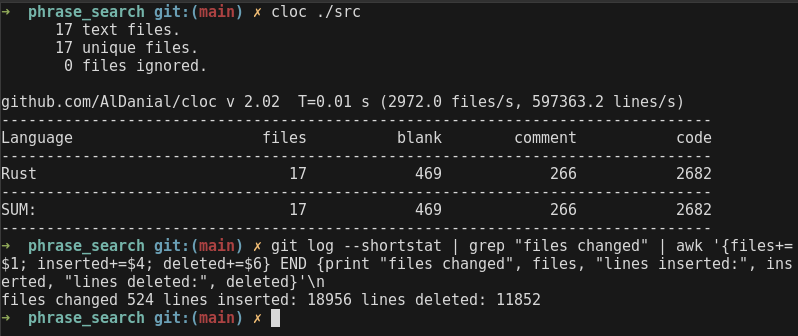
- At the beginning, I wasn’t planning on writing a blog post about it, but I invested so much time and the end result is so cool that I think it’s worth a blog post.
- I started writing a first version but didn’t like the direction it was going, so I decided to change it and here we are. So my plan is to show the current state of the project and try my best to remember and explain why things are the way they are. A lot of benchmarking and fine-tuning was done, so it’s almost impossible for me to remember everything. Maybe in some cases, I will go back in time to explain the reason certain optimizations were chosen and others I might just explain how they work. This post will probably be long, so grab some water/tea/coffee.
- Again, every piece of code that you will get to see has been rewritten a lot of times, I didn’t magically arrive at the solution.
- There will be a lot of
unsafekeywords, don’t be afraid of it. - We won’t talk about:
- Multi-threading, since this workload is trivially parallelizable (by sharding) it’s kinda easy to do it, and it scales pretty much linearly, so if you are curious about how this would perform on
Nthreads, just get the numbers and divide byN. - Things outside my code to make it faster, like enabling Huge Pages.
- The main focus will be on the search part, so there will be no focus on the indexing part, only when needed.
- Multi-threading, since this workload is trivially parallelizable (by sharding) it’s kinda easy to do it, and it scales pretty much linearly, so if you are curious about how this would perform on
- Benchmarking methodology:
- We are optimizing for raw latency, the lower the better.
- I have randomly selected a bunch of queries (each with a different bottleneck profile) and measured how each change impacted the performance.
- I ran each query 20 times to warm up the CPU, after that I ran the same query another 1000 times and collected the time taken as a whole and in each crucial step, with this we have time/iter.
- For those who say that that’s not a good benchmark and I should have used criterion with statistical analysis and blah blah blah… All I can say is both of my systems (spoiler alert) are pretty reproducible, up to 10us per iter.
- The core that I run the code is on my
isolcpuslist (the physical and mt part) and I usedtasksetevery time… Nothing else was running on the system while collecting data. - So after the CPU is warm, the time in each iteration is pretty damn consistent, so that’s why I consider this good enough.
- The dataset used is the same used by Doug, MS MARCO, containing 3.2M documents, around 22GB of data. It consists of a link, question, and a long answer, in this case, we only index the answer (so 20/22GB of data) (in the original article only 1M documents were used, but here we ingest all of it).
- Getting close to the end, there will be some benchmarks and comparisons against Meilisearch (a production-ready Search Engine, known for its good performance).
- Spec of both of my systems where I ran all of the benchmarks:
- Notebook (where most of the development took place): i5-1135G7 - 16GB
- Desktop (final results on this system): 9700x - 64GB (Spoiler)
- There will be a lot of source code for those who are interested, but the unnecessary ones will be collapsed, if you are not that interested you can just skip those.
- Also a huge thanks to all of the people who helped me through this, especially the super kind people on the Gamozo’s discord, who through the last year had to see me go crazy about intersection algorithms.
- Why am I doing this? Because I like it and wanted to nerd snipe some people.
What are we doing? And why do we care?
Do you know when you go to your favorite search engine and search for something using double quotes, like a passage of a book/article or something very specific? That’s called phrase search (sometimes exact search). What we are telling the search engine is that we want these exact words in this exact order (this varies from search engine to search engine, but that’s the main idea). In contrast, when searching by keywords (not in double quotes), we don’t care about the order or if it’s the exact word it may be a variation.
There is one big difference between these two: searching by keywords is relatively cheap when compared to doing a phrase search. In both cases, we are calculating the intersection between the reverse indexes (in the keyword search we may take the union, but for the sake of simplicity let’s assume the intersection), but in the phrase search, we need to keep track of where each token appeared to guarantee that we are looking for tokens close to each other.
So this makes phrase search way more computationally expensive. The conventional algorithm found in books is very slow, let’s take a look at this first and compare it with Doug’s brilliant idea.
How the conventional algorithm works

This algorithm (taken from Information Retrieval: Implementing and Evaluating Search Engines) analyzes one document at a time, so the nextPhrase function needs to be called for each document in the intersection of document IDs in the index.
Description (also taken from the book): Locates the first occurrence of a phrase after a given position. The function calls the next(t, i) method which returns the next position t after the position i. Similar to prev(t, i).
You don’t need to understand this algorithm, just that it is inefficient because of a lot of reasons:
- Intersection is expensive
- Analyzes one document at a time
- Not cache friendly, we are jumping around with the
nextandprevfunctions - Recursive
For a small collection of documents, this works fine, but imagine for large collections of 1M+ documents this will blow up quickly (hundreds of milliseconds, maybe even seconds per query), which is unacceptable for a real-time search engine, so not good at all.
The genius idea
How did Doug fix this? With a lot of clever bit hacking. The following example is taken from the blog post and summarized by me, also fixing some small mistakes in the examples (again, I highly recommend reading the original blog post).
Let’s say we want to index the following documents to be able to phrase search them in the future:
doc 0: "mary had a little lamb the lamb ate mary"
doc 1: "uhoh little mary dont eat the lamb it will get revenge"
doc 2: "the cute little lamb ran past the little lazy sheep"
doc 3: "little mary ate mutton then ran to the barn yard"
The inverted index will look something like this:
mary:
docs:
- 0:
posns: [0, 8]
- 1:
posns: [2]
little:
docs:
- 0:
posns: [3]
- 1:
posns: [1]
- 2:
posns: [2, 7]
- 3:
posns: [0]
lamb:
docs:
- 0:
posns: [4, 6]
- 1:
posns: [6]
- 2:
posns: [3]
...
To do a phrase search, we can connect two terms at a time, the left and right one. Searching by “mary had a little lamb” will result in searching by:
"mary"and"had"="mary had""mary had"and"a"="mary had a"- …
So we reuse the work done in the previous step, by connecting the right term with the previous one. Imagine the scenario where "mary had" occurs in the following positions: [1, 6] and "a" appears in the position [2], so "mary had a" occurs in the positions [2]. We keep doing this for the next token until we finish it.
The main idea to recreate and optimize this behavior was taken from Roaring Bitmaps, which is why it’s called Roaringish. We want to pack as much data as possible and avoid storing the positions for each document for each term separately.
Assuming that the pos <= 2^16 * 16 = 1048576 (i.e. the maximum document length is 1048576 tokens, which is very reasonable, it’s way more than Meilisearch for example, so this should be fine) allows us to decompose this value into two 16 bits, one representing the group and the other the value, where pos = group * 16 + value.
posns = [1, 5, 20, 21, 31, 100, 340]
groups = posns // 16 #[0, 0, 1, 1, 1, 6, 21]
values = posns % 16 #[1, 5, 4, 5, 15, 4, 4]
Since values < 15, we can pack even more data by bitwising each value of the same group into single 16 bit number
Group 0 Group 1 ... Group 21
0000000000100010 1000000000110000 ... 0000000000010000
(bits 1 and 5 set) (bits 4, 5, 15 set)
With this, we can pack the group and the values into a single 32-bit number by shifting the group and OR-ing it with the packed values, i.e. group_value = (group << 16) | values.
Group 0 | Group 1 ... | Group 21
0000000000000000 0000000000100010 | 0000000000000001 1000000000110000 ... | 0000000000010101 0000000000010000
(group 0) (bits 1 and 5 set) | (group 1) (bits 4, 5, 15 set) ... | (group 21) (bit 4 set)
Now to find if the left token is followed by the right token we can:
- Intersect the MSBs (group part)
Shift leftthe LSB bits from the left token by 1 (values part)Andthe LSBs- If there is at least one bit set in the LSBs after the
and, the left token is followed by the right token
For example, let’s assume the term “little” has the following positions.
Group 0 ... | Group 21
0000000000000000 0000000000100010 ... | 0000000000010101 0000000000010100
And “lamb”.
Group 1 ... | Group 21
0000000000000001 0000000000100010 ... | 0000000000010101 0000000001001000
The group 21 is in the intersection, so:
(0000000000010100 << 1) & 0000000001001000 = 0000000000001000
With this “little lamb” is found in group 21 value 3, i.e 21*16+3 = 339.
And the magical part is: To avoid having to analyze one document at a time, we can pack the document ID (assuming a 32-bit document ID) into the 32 MSB of a 64-bit number, while the LSB are the group and value. packed = (doc_id << 32) | group_value.
When calculating the intersection, we take the document ID and group (48 MSBs). With this, we can search the whole index in a single shot. So in the end, we have a single continuous array of data, with all document IDs and positions that contain that token.
Pretty cool.
Note: For those who are paying attention, you might have spotted a problem. We will talk about this later.
How my version works ?
The idea behind my implementation is similar, but with a lot of extra steps. Here we have a brief overview of how it all works, and later we will explore each step in depth.
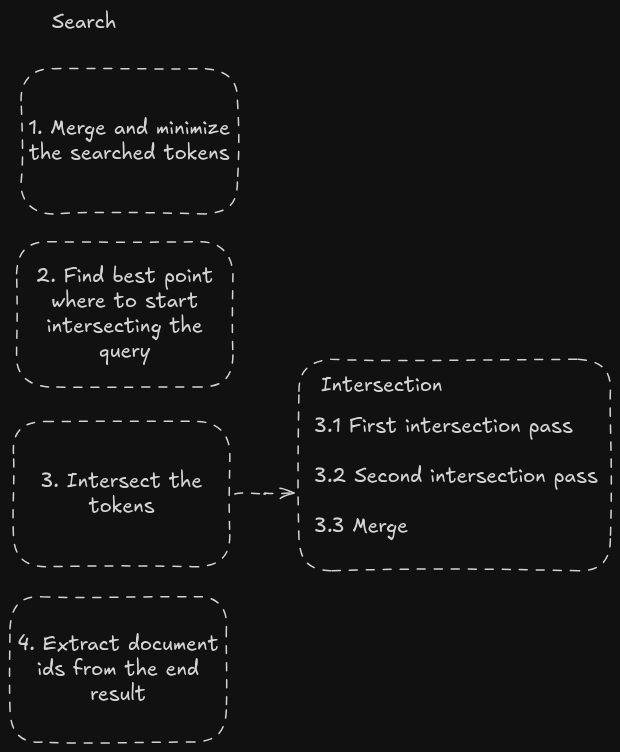
Steps 1 and 2 are here to help us reduce as much as possible the time spent on step 3, since it’s the most expensive one. Both of them try to be smart and find the best pattern for us to tackle the same problem by reducing the search space.
Most of our time will be spent on step 3, but step 1 is pretty cool.
Code for the main body of the search function (you can ignore if you want)
fn search<I: Intersect>(
&self,
q: &str,
common_tokens: &HashSet<Box<str>>,
mmap: &Mmap,
) -> Vec<u32> {
let tokens = Tokens::new(q);
let tokens = tokens.as_ref();
if tokens.is_empty() {
return Vec::new();
}
let rotxn = self.env.read_txn().unwrap();
if tokens.len() == 1 {
return self
.get_roaringish_packed(&rotxn, tokens.first().unwrap(), mmap)
.map(|p| p.get_doc_ids())
.unwrap_or_default();
}
// Step 1
let bump = Bump::with_capacity(tokens.reserve_len() * 5);
let (final_tokens, token_to_packed) =
self.merge_and_minimize_tokens(&rotxn, tokens, common_tokens, mmap, &bump);
let Some(final_tokens) = final_tokens else {
return Vec::new();
};
if final_tokens.next.is_none() {
return token_to_packed
.get(&final_tokens.tokens)
.unwrap()
.get_doc_ids();
}
let final_tokens: Vec<_> = final_tokens.iter().copied().collect();
// Step 2
let mut min = usize::MAX;
let mut i = usize::MAX;
for (j, ts) in final_tokens.windows(2).enumerate() {
let l0 = token_to_packed.get(&ts[0]).unwrap().len();
let l1 = token_to_packed.get(&ts[1]).unwrap().len();
let l = l0 + l1;
if l <= min {
i = j;
min = l;
}
}
let lhs = &final_tokens[i];
let mut lhs_len = lhs.len() as u32;
let lhs = token_to_packed.get(lhs).unwrap();
let rhs = &final_tokens[i + 1];
let mut rhs_len = rhs.len() as u32;
let rhs = token_to_packed.get(rhs).unwrap();
// Step 3
let mut result = lhs.intersect::<I>(*rhs, lhs_len);
let mut result_borrow = BorrowRoaringishPacked::new(&result);
let mut left_i = i.wrapping_sub(1);
let mut right_i = i + 2;
// Step 2 and 3
loop {
let lhs = final_tokens.get(left_i);
let rhs = final_tokens.get(right_i);
match (lhs, rhs) {
(Some(t_lhs), Some(t_rhs)) => {
let lhs = token_to_packed.get(t_lhs).unwrap();
let rhs = token_to_packed.get(t_rhs).unwrap();
if lhs.len() <= rhs.len() {
lhs_len += t_lhs.len() as u32;
result = lhs.intersect::<I>(result_borrow, lhs_len);
result_borrow = BorrowRoaringishPacked::new(&result);
left_i = left_i.wrapping_sub(1);
} else {
result = result_borrow.intersect::<I>(*rhs, rhs_len);
result_borrow = BorrowRoaringishPacked::new(&result);
lhs_len += rhs_len;
rhs_len = t_rhs.len() as u32;
right_i += 1;
}
}
(Some(t_lhs), None) => {
let lhs = token_to_packed.get(t_lhs).unwrap();
lhs_len += t_lhs.len() as u32;
result = lhs.intersect::<I>(result_borrow, lhs_len);
result_borrow = BorrowRoaringishPacked::new(&result);
left_i = left_i.wrapping_sub(1);
}
(None, Some(t_rhs)) => {
let rhs = token_to_packed.get(t_rhs).unwrap();
result = result_borrow.intersect::<I>(*rhs, rhs_len);
result_borrow = BorrowRoaringishPacked::new(&result);
lhs_len += rhs_len;
rhs_len = t_rhs.len() as u32;
right_i += 1;
}
(None, None) => break,
}
}
// Step 4
result_borrow.get_doc_ids()
}
So you might have noticed that the intersection is composed of two phases. Why is that? There is an annoying issue with Roaringish due to the edge case where value bits are on the boundary of the group, and calculating the intersection would lead to an incorrect result (that’s the issue mentioned above). For example:
t_0: Group 0 t_1: Group 1
0000000000000000 1000000000000000 0000000000000001 0000000000000001
It’s obvious in this example that t_0 is followed by t_1, but the conventional intersection would fail in this case. To solve this, I decided to do the intersection in two passes: the first calculates the “normal” intersection, and the second handles this annoying edge case.
Note: I don’t know how Doug solved this. I haven’t checked the code. But this issue is mentioned in the article.
Use your indexing time wisely
In the field of Information Retrieval and Databases, one way to reduce the search/query time is to pre-calculate more during indexing/data ingestion.
One of the techniques that I used very early on in the making of this project is merging tokens during indexing (similar to n-grams).
I had a few constraints when implementing this: final index size, memory consumption while indexing, and indexing time. I wanted to minimize all of them.
Why do I want to minimize those metrics? For most of the time, I developed this on a 16GB machine with a few hundred gigabytes left on disk, so I was very constrained in this sense. And for indexing time, since I’m developing, I want to iterate fast, so if I need to re-index the whole thing, it can’t take a long time.
Note: If you look at the source code on Github, you will see that my indexing to this day is done on a single thread. The reason is that I can easily achieve high memory consumption on a single thread. The reason why it consumes so much memory is that most of the indexing is done and cached in RAM to be as fast as possible. Indexing these 3.2M documents only takes around 30/35 minutes on a single thread.
How to solve this problem?
The idea is to only merge common tokens. You might ask: “What is a common token?” Well, it’s simple: they are the tokens that appear the most in the collection. You can specify how many of the top tokens to consider as common ones, or as a percentage. I arbitrarily chose the top 50 tokens. There is also a parameter for the maximum sequence length, in this case, I used 3.
Increasing these two parameters will make the index size, indexing memory consumption, and indexing time grow, so it’s a careful balance. But the more you compute at indexing time, the better. If you can afford more, go for it.
The good thing about merging common tokens is that they are the most expensive in general to compute the intersection, so removing them makes things a lot faster.
Here is an example, where C_n is a common token and R_n is a rare token (rare tokens are all of the other tokens that are not common).
C_0 R_1 C_2 C_3 C_4 R_5 R_6 ... R_x C_y R_z ...
This sequence of tokens will generate the following tokens and positions:
C_0: 0
C_0 R_1: 0
R_1: 1
R_1 C_2: 1
R_1 C_2 C_3: 1
C_2: 2
C_2 C_3: 2
C_2 C_3 C_4: 2
C_3: 3
C_3 C_4: 3
C_3 C_4 R_5: 3
C_4: 4
C_4 R_5: 4
R_5: 5
R_6: 6
...
R_x: x
R_x C_y: x
C_y: y
C_y R_z: y
R_z: z
Doing this allows us to reduce the number of intersections done at search time.
Why are you merging up to one rare token at the beginning or at the end? Let’s consider that someone searched for C_0 R_1 C_2 C_3. If we don’t do this merge, we would end up searching for C_0, R_1, C_2 C_3, and this is bad. As established, intersecting common tokens is a problem, so it’s way better to search C_0 R_1, C_2 C_3. I learned this the hard way…
This brings us to the next topic that is done only at search time, the minimization step.
Dynamic Programming in the wild
Let’s use the same example as above, but this time the person searched for R_1 C_2 C_3 C_4 R_5. Since we have all possible combinations from the merge phase, we can be smart and try to predict which combination of these tokens will take less time to be intersected.
At search time, we can be greedy while merging, but this might not lead to the fastest intersection combination of tokens. In the greedy version, we will compute the intersection of R_1 C_2 C_3, C_4 R_5, but it might be better to compute R_1, C_2 C_3 C_4, R_5 or R_1 C_2, C_3 C_4 R_5 and so on…
It’s 100% worth spending time here before computing the intersection. I learned this the hard way…
Does this look like some kind of problem to you? Yes, Dynamic Programming. Sometimes these problems appear in the wild, so yes, LeetCode is not a lie (I don’t like LeetCode).
How can we solve this? First, let’s list what we need to do:
- List all possible combinations of tokens (in a smart way)
- Estimate the cost of the intersection for that combination (in a smart way).
Yeah, this is expensive… Usually, when you find a DP problem in the wild, what do you do? Google a solution for it. In my case, this wasn’t a possibility. I created this problem, so now I need to solve it.
It didn’t take too long for me to get a solution since the algorithm isn’t that hard. We can also use some memoization to amortize the cost. Here is the POC I wrote in Python (very poorly optimized) while trying to find a solution for this problem.
# arr: tokens
# scores: score for each possible token combination
# N: maximum sequence len
def minimize(arr, scores, N):
if len(arr) == 0:
return (0, [])
final_score = float('inf')
choices = []
e = min(N, len(arr))
sub_arr = arr[:e]
for j in range(len(sub_arr), 0, -1):
sub_sub_arr = sub_arr[:j]
rem = arr[j:]
concated = ' '.join(sub_sub_arr)
score = scores[concated]
(rem_score, rem_choices) = minimize(rem, scores, N)
calc_score = score + rem_score
if calc_score < final_score:
choices.clear()
final_score = calc_score
choices.append(concated)
for r_choise in rem_choices:
choices.append(r_choise)
return (final_score, choices)
This version is very simple, it doesn’t do the correct merging of tokens nor has any optimization/memoization, but what is important is the idea. As said previously, we want to minimize the cost/score, since intersection is computed in O(n+m) that’s what we are aiming to minimize. There are other approaches to the cost function, like trying to find the combination that leads to the smallest possible size of a single token.
Let’s do an example of how this works. Since here we just merge tokens without caring if they are common or rare, let’s assume the following query t_0 t_1 t_2 t_3 t_4:
For each call of the function, we loop over all possible merges of the remaining tokens. So we get the cost for the token t_0 t_1 t_2 and call the function recursively for t_3 t_4 and so on. The call graph would look like this:
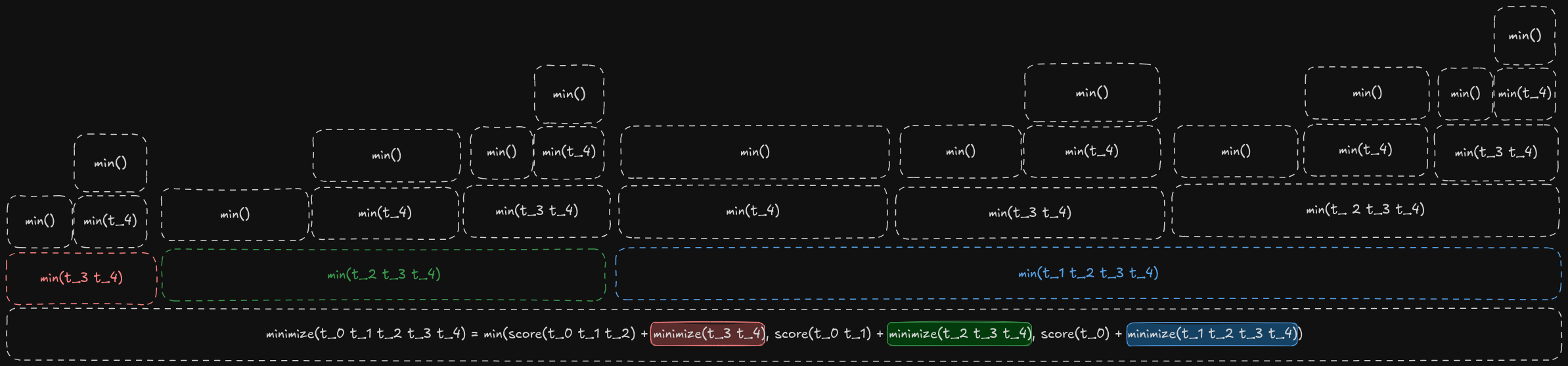
As you can see, there is a lot of repeated work being done, that’s why memoization is needed. Also, reducing the recursion depth helps. So in the final Rust version, I did exactly that, but tried my best to optimize this, also I needed to respect how the merge of tokens works.
If you are going to read the following code, you can just ignore all of the const generics, they are not important for your understanding…
Code for merge and minimize (you can ignore if you want)
#[derive(Clone, Copy)]
struct RefTokens<'a> {
tokens: &'a str,
positions: &'a [(usize, usize)],
}
impl RefTokens<'_> {
fn len(&self) -> usize {
self.positions.len()
}
fn tokens(&self) -> &str {
let (b, e) = self.range();
unsafe { self.tokens.get_unchecked(b..e) }
}
fn split_at(&self, i: usize) -> (Self, Self) {
let (l, r) = self.positions.split_at(i);
(
Self {
tokens: self.tokens,
positions: l,
},
Self {
tokens: self.tokens,
positions: r,
},
)
}
fn ref_token_iter(&self) -> impl Iterator<Item = Self> + '_ {
(0..self.positions.len())
.map(|i| Self {
tokens: self.tokens,
positions: &self.positions[i..i+1]
})
}
}
impl Hash for RefTokens<'_> {
fn hash<H: std::hash::Hasher>(&self, state: &mut H) {
self.tokens().hash(state);
}
}
#[derive(Clone, Copy, Debug)]
struct RefTokenLinkedList<'a, 'alloc> {
tokens: RefTokens<'a>,
next: Option<&'alloc RefTokenLinkedList<'a, 'alloc>>,
}
#[inline(never)]
fn merge_and_minimize_tokens<'a, 'b, 'alloc>(
&self,
rotxn: &RoTxn,
tokens: RefTokens<'a>,
common_tokens: &HashSet<Box<str>>,
mmap: &'b Mmap,
bump: &'alloc Bump,
) -> (
Vec<RefTokens<'a>>,
GxHashMap<RefTokens<'a>, BorrowRoaringishPacked<'b, Aligned>>,
) {
#[inline(always)]
fn check_before_recursion<'a, 'b, 'alloc, D>(
me: &DB<D>,
rotxn: &RoTxn,
tokens: RefTokens<'a>,
token_to_packed: &mut GxHashMap<RefTokens<'a>, BorrowRoaringishPacked<'b, Aligned>>,
mmap: &'b Mmap,
memo_token_to_score_choices: &mut GxHashMap<
RefTokens<'a>,
(usize, &'alloc RefTokenLinkedList<'a, 'alloc>),
>,
bump: &'alloc Bump,
) -> Option<usize>
where
D: for<'c> Serialize<HighSerializer<AlignedVec, ArenaHandle<'c>, rkyv::rancor::Error>>
+ Archive
+ 'static,
{
if tokens.len() != 1 {
return None;
}
let score = match token_to_packed.entry(tokens) {
Entry::Occupied(e) => e.get().len(),
Entry::Vacant(e) => match me.get_roaringish_packed(rotxn, &tokens[0], mmap) {
Some(packed) => {
let score = packed.len();
e.insert(packed);
let linked_list = bump.alloc(RefTokenLinkedList { tokens, next: None });
memo_token_to_score_choices.insert(tokens, (score, linked_list));
score
}
None => 0,
},
};
Some(score)
}
#[allow(clippy::too_many_arguments)]
fn inner_merge_and_minimize_tokens<'a, 'b, 'c, 'alloc, D>(
me: &DB<D>,
rotxn: &RoTxn,
tokens: RefTokens<'a>,
common_tokens: &HashSet<Box<str>>,
token_to_packed: &mut GxHashMap<RefTokens<'a>, BorrowRoaringishPacked<'b, Aligned>>,
mmap: &'b Mmap,
memo_token_to_score_choices: &mut GxHashMap<
RefTokens<'a>,
(usize, &'alloc RefTokenLinkedList<'a, 'alloc>),
>,
bump: &'alloc Bump,
) -> usize
where
D: for<'d> Serialize<HighSerializer<AlignedVec, ArenaHandle<'d>, rkyv::rancor::Error>>
+ Archive
+ 'static,
{
const { assert!(MAX_WINDOW_LEN.get() == 3) };
let mut final_score = usize::MAX;
let mut best_token_choice = None;
let mut best_rem_choice = None;
let mut end = tokens
.iter()
.skip(1)
.take(MAX_WINDOW_LEN.get() - 1)
.take_while(|t| common_tokens.contains(*t))
.count()
+ 2;
if common_tokens.contains(&tokens[0]) {
end += 1;
}
end = end.min(MAX_WINDOW_LEN.get() + 1).min(tokens.len() + 1);
for i in (1..end).rev() {
let (tokens, rem) = tokens.split_at(i);
let score = match token_to_packed.entry(tokens) {
Entry::Occupied(e) => e.get().len(),
Entry::Vacant(e) => {
match me.get_roaringish_packed(rotxn, tokens.tokens(), mmap) {
Some(packed) => {
let score = packed.len();
e.insert(packed);
score
}
None => return 0,
}
}
};
let mut rem_score = 0;
if !rem.is_empty() {
rem_score = match memo_token_to_score_choices.get(&rem) {
Some(r) => r.0,
None => {
match check_before_recursion(
me,
rotxn,
rem,
token_to_packed,
mmap,
memo_token_to_score_choices,
bump,
) {
Some(score) => score,
None => inner_merge_and_minimize_tokens(
me,
rotxn,
rem,
common_tokens,
token_to_packed,
mmap,
memo_token_to_score_choices,
bump,
),
}
}
};
if rem_score == 0 {
return 0;
}
}
let calc_score = score + rem_score;
if calc_score < final_score {
final_score = calc_score;
best_token_choice = Some(tokens);
if let Some((_, rem_choices)) = memo_token_to_score_choices.get(&rem) {
best_rem_choice = Some(*rem_choices);
};
}
}
let choices = match (best_token_choice, best_rem_choice) {
(None, None) => return 0,
(None, Some(_)) => return 0,
(Some(tokens), None) => bump.alloc(RefTokenLinkedList { tokens, next: None }),
(Some(tokens), Some(rem)) => bump.alloc(RefTokenLinkedList {
tokens,
next: Some(rem),
}),
};
memo_token_to_score_choices.insert(tokens, (final_score, choices));
final_score
}
#[inline(never)]
fn no_common_tokens<'a, 'b, 'alloc, D>(
me: &DB<D>,
rotxn: &RoTxn,
tokens: RefTokens<'a>,
mmap: &'b Mmap,
) -> (
Vec<RefTokens<'a>>,
GxHashMap<RefTokens<'a>, BorrowRoaringishPacked<'b, Aligned>>,
)
where
D: for<'c> Serialize<HighSerializer<AlignedVec, ArenaHandle<'c>, rkyv::rancor::Error>>
+ Archive
+ 'static,
{
let l = tokens.len();
let mut token_to_packed = GxHashMap::with_capacity(l);
let mut v = Vec::with_capacity(l);
for token in tokens.ref_token_iter() {
match me.get_roaringish_packed(rotxn, token.tokens(), mmap) {
Some(packed) => token_to_packed.insert(token, packed),
None => return (Vec::new(), GxHashMap::new()),
};
v.push(token);
}
return (v, token_to_packed);
}
if common_tokens.is_empty() {
return no_common_tokens(self, rotxn, tokens, mmap);
}
let len = tokens.reserve_len();
let mut memo_token_to_score_choices = GxHashMap::with_capacity(len);
let mut token_to_packed = GxHashMap::with_capacity(len);
let score = match check_before_recursion(
self,
rotxn,
tokens,
&mut token_to_packed,
mmap,
&mut memo_token_to_score_choices,
bump,
) {
Some(score) => score,
None => inner_merge_and_minimize_tokens(
self,
rotxn,
tokens,
common_tokens,
&mut token_to_packed,
mmap,
&mut memo_token_to_score_choices,
bump,
),
};
if score == 0 {
return (Vec::new(), GxHashMap::new());
}
match memo_token_to_score_choices.remove(&tokens) {
Some((_, choices)) => {
let v = choices.iter().copied().collect();
(v, token_to_packed)
},
None => (Vec::new(), GxHashMap::new()),
}
}
This code is kinda long and convoluted (also ugly IMHO), so I will not go through it, but there are a few things I would like to talk about. For a long time, the implementation was much more naive and simple, and this was enough until other parts became way more optimized, and this started being the bottleneck, especially for long queries.
So don’t optimize things that are not your bottleneck until they become it.
The input tokens in the original version were a &[&str], and the memoization was still done using a HashMap, which is bad since the token sequence is the key of the hashmap. Hashing strings is already slow enough, but hashing multiple strings and combining these hashes is ridiculously slow. I used flamegraph to find this bottleneck. Another thing I noticed was that a lot of time was being spent on allocations.
To fix both of these problems, I decided to be a little bit smarter. Since allocations in this case are all tied to the lifetime of the merge_and_minimize_tokens function, we can just put everything into a bump/arena allocator and free it together when finished.
Also, putting things into the same bump allocator allows us to more easily manipulate the lifetimes to our own will. That’s why we have the 'alloc lifetime.
The type RefTokens is a type that holds a “list of tokens”, but it’s just a lie. What we hold is the original string and a list of pairs, the beginning and end index of each token. We can use this to slice the original string and have the “list of tokens”. This is helpful because now the hash function can be implemented around this fact, so in the end, we are just hashing a single string. The 'a lifetime is the lifetime of the original query string.
And finally, we have RefTokenLinkedList. We are basically creating a linked list of RefTokens, which will represent the final merge of the tokens. If you look closely at this type declaration, it accepts 'a and 'alloc, and that’s why using a bump allocator makes things easier. The next reference/pointer of the linked list is of type Option<&'alloc RefTokenLinkedList<'a, 'alloc>>. So when someone says to you that it’s hard to make a linked list in Rust, now you know that it’s not /s.
I usually go with AHash as my hash function in Rust (and for a long time it was used in this function), but this time I decided to experiment with GxHash, and I was pleasantly surprised that it was faster. I will take this easy win.
One other small optimization that we can make is to reduce the size of the call graph by checking things before calling the function again.
You are only as good as your reverse index
No optimization will save you from having a poor reverse index implementation, so just like when you go to the gym and want to skip leg day, don’t skip on the technologies and structure of your index.
My reverse index, like any other part, has gone through drastic changes during development (that’s why having a low index time is good). But there are two pieces of technology that were the heart and soul in every version: heed (LMDB) and rkyv. A special shoutout to the creator of rkyv (David Koloski), a super helpful person who released the 0.8.X version that allowed me to use the unaligned feature and is super active on their discord, helping people by answering questions and fixing bugs in minutes when they are reported.
Now let’s go through the structure of my reverse index. We have 3 databases, that’s it. Simple and effective. The first database holds some metadata about the index, the second holds the internal document ID to the document itself, and the third holds the token to the Roaringish Packed (continuous block of memory of u64s (u32 for the document ID, u16 for the index, and u16 for the values as discussed above)).
Let’s take a look at the signature of the index function:
fn index<S, D, I>(&self, docs: I, path: &Path, db_size: usize) -> u32
where
S: AsRef<str>,
I: IntoIterator<Item = (S, D)>,
D: for<'a> Serialize<HighSerializer<AlignedVec, ArenaHandle<'a>, rkyv::rancor::Error>>
+ Archive
+ 'static
{}
What is important is the type of docs, which is an iterator that returns a tuple (&str, D), where the first element is the content of the document and D (as long as D is serializable by rkyv) is the stored version of the document. These two can be different, and you might ask why?
Imagine a scenario where you want to index a bunch of text documents on your hard drive but want to save disk space. Instead of saving the content of the documents in the database when you call the index function, you pass the content of the document and the path of the document as the type D. This way, you just save the path of the file that has the specified content.
This is just one example. Imagine if you have things stored in an external database and just need to save the ID…
So remember a few paragraphs above where I said that the third database saves the token to the Roaringish Packed? I kinda lied to you, sorry… In reality, we have an extra moving part, not because I want it, but because I couldn’t figure out how to make heed behave the way I want.
For the fun part of this blog post (we will get there in the future, bear with me), I need the continuous block that represents the Roaringish Packed to be aligned to a 64-byte boundary, but you can’t enforce this with LMDB and consequently heed. I really tried, but when you insert things into the DB, it messes up the alignment of the rest of the values, so it doesn’t work trying to insert things already aligned.
Fixing this isn’t hard if we add an additional big file that has all of the Roaringish Packed aligned to a 64-byte boundary. So in the LMDB, we only store an offset and length. But how do we align the data?
This file will be mmaped, so it’s guaranteed to be page-aligned (4k). With this, we know the alignment of the base of the file when constructing it, so we just pad some bytes before the beginning of the next Roaringish Packed if needed.
Also, another small optimization that I thought would make a bigger difference is to madvise the retrieved range as sequential read.
Code for retrieving the Roaringish Packed from the index (you can ignore if you want)
fn get_roaringish_packed<'a>(
&self,
rotxn: &RoTxn,
token: &str,
mmap: &'a Mmap,
) -> Option<BorrowRoaringishPacked<'a, Aligned>> {
let offset = self.db_token_to_offsets.get(rotxn, token).unwrap()?;
Self::get_roaringish_packed_from_offset(offset, mmap)
}
fn get_roaringish_packed_from_offset<'a>(
offset: &ArchivedOffset,
mmap: &'a Mmap,
) -> Option<BorrowRoaringishPacked<'a, Aligned>> {
let begin = offset.begin.to_native() as usize;
let len = offset.len.to_native() as usize;
let end = begin + len;
let (l, packed, r) = unsafe { &mmap[begin..end].align_to::<u64>() };
assert!(l.is_empty());
assert!(r.is_empty());
mmap.advise_range(memmap2::Advice::Sequential, begin, len)
.unwrap();
Some(BorrowRoaringishPacked::new_raw(packed))
}
You might ask: Is it safe to align to u64? And the answer is yes, if the file is properly constructed, it should be 64-byte aligned, which is bigger than the 8-byte alignment needed for u64. Also, checking if l and r are empty helps us ensure that everything is working properly.
We can still be smarter
At this point, we have the merged and minimized tokens, so in theory, we have everything needed to start intersecting them, right? Right, but… What if I tell you that we can still try to reduce our search space by doing something that I call smart execution?
Similar to the minimize step, we can reduce the number of computed intersections, but in this case, we are just changing the order in which we compute the intersections. Since this operation is associative (but not commutative), we can group/start the computation at any point and achieve the same result.
However, in this case, we can’t be as aggressive as the minimize step because the score would be the final size of the intersection (we only have an upper bound), and to know this, we need to compute the intersection itself.
With this in mind, we can be a little bit more naive but still good enough: start intersecting by the pair that leads to the smallest sum of lengths (we could also start with the token that has the smallest Roaringish Packed length and intersect with the smallest adjacent, but I prefer the first option).
let mut min = usize::MAX;
let mut i = usize::MAX;
for (j, ts) in final_tokens.windows(2).enumerate() {
let l0 = token_to_packed.get(&ts[0]).unwrap().len();
let l1 = token_to_packed.get(&ts[1]).unwrap().len();
let l = l0 + l1;
if l <= min {
i = j;
min = l;
}
}
let lhs = &final_tokens[i];
let mut lhs_len = lhs.len() as u32;
let lhs = token_to_packed.get(lhs).unwrap();
benchmarking and fine
let rhs = &final_tokens[i + 1];
let mut rhs_len = rhs.len() as u32;
let rhs = token_to_packed.get(rhs).unwrap();
let mut result = lhs.intersect::<I>(*rhs, lhs_len);
let mut result_borrow = BorrowRoaringishPacked::new(&result);
let mut left_i = i.wrapping_sub(1);
let mut right_i = i + 2;
Just loop over every adjacent pair and compute the sum of the lengths and use the smallest as the starting point. After this we intersect with the left or right token depeding which has the smallest size.
loop {
let lhs = final_tokens.get(left_i);
let rhs = final_tokens.get(right_i);
match (lhs, rhs) {
(Some(t_lhs), Some(t_rhs)) => {
// ...
}
(Some(t_lhs), None) => {
// ...
}
(None, Some(t_rhs)) => {
// ...
}
(None, None) => break,
}
}
Code for smart execution as a whole (you can ignore if you want)
// This collect is almost free when compared with the rest, so don't
// be bothered by it.
let final_tokens: Vec<_> = final_tokens.iter().copied().collect();
let mut min = usize::MAX;
let mut i = usize::MAX;
for (j, ts) in final_tokens.windows(2).enumerate() {
let l0 = token_to_packed.get(&ts[0]).unwrap().len();
let l1 = token_to_packed.get(&ts[1]).unwrap().len();
let l = l0 + l1;
if l <= min {
i = j;
min = l;
}
}
let lhs = &final_tokens[i];
let mut lhs_len = lhs.len() as u32;
let lhs = token_to_packed.get(lhs).unwrap();
let rhs = &final_tokens[i + 1];
let mut rhs_len = rhs.len() as u32;
let rhs = token_to_packed.get(rhs).unwrap();
let mut result = lhs.intersect::<I>(*rhs, lhs_len);
let mut result_borrow = BorrowRoaringishPacked::new(&result);
let mut left_i = i.wrapping_sub(1);
let mut right_i = i + 2;
loop {
let lhs = final_tokens.get(left_i);
let rhs = final_tokens.get(right_i);
match (lhs, rhs) {
(Some(t_lhs), Some(t_rhs)) => {
let lhs = token_to_packed.get(t_lhs).unwrap();
let rhs = token_to_packed.get(t_rhs).unwrap();
if lhs.len() <= rhs.len() {
lhs_len += t_lhs.len() as u32;
result = lhs.intersect::<I>(result_borrow, lhs_len);
result_borrow = BorrowRoaringishPacked::new(&result);
left_i = left_i.wrapping_sub(1);
} else {
result = result_borrow.intersect::<I>(*rhs, rhs_len);
result_borrow = BorrowRoaringishPacked::new(&result);
lhs_len += rhs_len;
rhs_len = t_rhs.len() as u32;
right_i += 1;
}
}
(Some(t_lhs), None) => {
let lhs = token_to_packed.get(t_lhs).unwrap();
lhs_len += t_lhs.len() as u32;
result = lhs.intersect::<I>(result_borrow, lhs_len);
result_borrow = BorrowRoaringishPacked::new(&result);
left_i = left_i.wrapping_sub(1);
}
(None, Some(t_rhs)) => {
let rhs = token_to_packed.get(t_rhs).unwrap();
result = result_borrow.intersect::<I>(*rhs, rhs_len);
result_borrow = BorrowRoaringishPacked::new(&result);
lhs_len += rhs_len;
rhs_len = t_rhs.len() as u32;
right_i += 1;
}
(None, None) => break,
}
}
This leads to another huge win, especially for queries that have a super rare token in the middle of it. This cuts the search space by a lot, making every single subsequent intersection faster.
Here begins the fun
Now that the boring stuff is behind us, let’s start the fun part. Again, just as a reminder on how the intersection works: we do two phases of intersection, one for the conventional intersection and another for the bits that would cross the group boundary, and in the end, we merge these two.
In this section, we will take a look at assembly, some cool tools to analyze this assembly, AVX-512, differences in the microarchitecture of AMD and Intel chips, emulation of instructions, and a lot more. So again, sorry to bother you with all of the previous stuff, but it was important.
For your better understanding of how the two intersection phases work, let’s start with the naive version and build our way to the SIMD one.
The intersection used by the search function is a generic, and the type needs to implement the Intersect trait.
trait Intersect {
fn intersect<const FIRST: bool>(
lhs: BorrowRoaringishPacked<'_, Aligned>,
rhs: BorrowRoaringishPacked<'_, Aligned>,
lhs_len: u32,
) -> (Vec<u64, Aligned64>, Vec<u64, Aligned64>) {
let mut lhs_i = 0;
let mut rhs_i = 0;
let buffer_size = Self::intersection_buffer_size(lhs, rhs);
let mut i = 0;
let mut packed_result: Box<[MaybeUninit<u64>], Aligned64> =
Box::new_uninit_slice_in(buffer_size, Aligned64::default());
let mut j = 0;
let mut msb_packed_result: Box<[MaybeUninit<u64>], Aligned64> = if FIRST {
Box::new_uninit_slice_in(lhs.0.len() + 1, Aligned64::default())
} else {
Box::new_uninit_slice_in(0, Aligned64::default())
};
let add_to_group = (lhs_len / 16) as u64 * ADD_ONE_GROUP;
let lhs_len = (lhs_len % 16) as u16;
let msb_mask = !(u16::MAX >> lhs_len);
let lsb_mask = !(u16::MAX << lhs_len);
Self::inner_intersect::<FIRST>(
lhs,
rhs,
&mut lhs_i,
&mut rhs_i,
&mut packed_result,
&mut i,
&mut msb_packed_result,
&mut j,
add_to_group,
lhs_len,
msb_mask,
lsb_mask,
);
let (packed_result_ptr, a0) = Box::into_raw_with_allocator(packed_result);
let (msb_packed_result_ptr, a1) = Box::into_raw_with_allocator(msb_packed_result);
unsafe {
(
Vec::from_raw_parts_in(packed_result_ptr as *mut _, i, buffer_size, a0),
if FIRST {
Vec::from_raw_parts_in(msb_packed_result_ptr as *mut _, j, lhs.0.len() + 1, a1)
} else {
Vec::from_raw_parts_in(msb_packed_result_ptr as *mut _, 0, 0, a1)
},
)
}
}
#[allow(clippy::too_many_arguments)]
fn inner_intersect<const FIRST: bool>(
lhs: BorrowRoaringishPacked<'_, Aligned>,
rhs: BorrowRoaringishPacked<'_, Aligned>,
lhs_i: &mut usize,
rhs_i: &mut usize,
packed_result: &mut Box<[MaybeUninit<u64>], Aligned64>,
i: &mut usize,
msb_packed_result: &mut Box<[MaybeUninit<u64>], Aligned64>,
j: &mut usize,
add_to_group: u64,
lhs_len: u16,
msb_mask: u16,
lsb_mask: u16,
);
fn intersection_buffer_size(
lhs: BorrowRoaringishPacked<'_, Aligned>,
rhs: BorrowRoaringishPacked<'_, Aligned>,
) -> usize;
}
As you can see, the intersect and inner_intersect functions have a const generic that conditionally enables code depending on the intersection phase.
Note: You might not like this, but I personally prefer having this constant flag rather than duplicating a bunch of code.
The intersect function is pre-implemented and is responsible for allocating the result buffers. If you look closely, msb_packed_result has 0 capacity in the second phase. The reason is that the first phase is responsible for the normal intersection and finding the candidates for the second intersection phase, which are saved in the msb_packed_result. That’s why we don’t need this variable in the second pass.
Another funny thing you might have noticed is the Aligned64 type. Like the values retrieved from the mmap, I need this to be 64-byte aligned. One easy way to solve this is to specify a custom allocator for the container. In this case, I created an allocator that changes the alignment of the inner type to be whatever I want. Here is the code.
#[derive(Default)]
struct AlignedAllocator<const N: usize>;
unsafe impl<const N: usize> Allocator for AlignedAllocator<N> {
fn allocate(
&self,
layout: std::alloc::Layout,
) -> Result<std::ptr::NonNull<[u8]>, std::alloc::AllocError> {
unsafe {
let p = alloc(layout.align_to(N).unwrap());
let s = std::ptr::slice_from_raw_parts_mut(p, layout.size());
#[cfg(debug_assertions)]
return NonNull::new(s).ok_or(std::alloc::AllocError);
#[cfg(not(debug_assertions))]
return Ok(NonNull::new_unchecked(s));
}
}
unsafe fn deallocate(&self, ptr: std::ptr::NonNull<u8>, layout: std::alloc::Layout) {
dealloc(ptr.as_ptr(), layout.align_to(N).unwrap());
}
}
type Aligned64 = AlignedAllocator<64>;
Explanation on why I use Box<[MaybeUninit<T>] (you can ignore if you want)
You might also have noticed something different: Why am I not using Vec? Because it’s bad… I’m kidding, it’s not bad, but it makes the life of the compiler harder when optimizing, especially because I know the upper bound of my buffers, I can pre-allocate them. But again, you might ask Why are you not using Vec::with_capacity? Because the compiler is dumb, even if you specify the capacity, when pushing elements it will create a branch instruction (pretty bad).
Look at the following assembly for each function vec_with_capacity, box_uninit and vec_within_capacity (you can change the function by clicking on the top left tab (besides the Export button)), all of the loops are in the bottom right corner of the graph.
The vec_with_capacity adds one big function call to RawVec<T,A>::grow_one (even though we are adding the same amount of elements as specified in the capacity), and if you look at the assembly of this function, it has a branch. Do you know what branching does to optimizers? It messes with their ability to vectorize. If you look at box_uninit or vec_within_capacity, the compiler even vectorized the loop for us.
I personally prefer the syntax of box_uninit, that’s why I use it instead of vec_within_capacity (it also requires a feature flag, even though that’s not a problem).
So here is the reason why you are going to see Box<[MaybeUninit<T>] here on out.
The other responsibility of the intersect function has something to do with the lhs_len parameter. Let’s try to understand what this parameter means first. Assume the following token merger/minimization:
len: 50 10 5 40
...| t_0 t_1 | t_2 t_3 t_4 | t_5 | t_6 t_7 | ...
^
Start intersecting here
- First intersection:
t_2 t_3 t_4andt_5, the lhs token has a length of 3 and rhs has a length of 1. Let’s save this into two temporary variablestemp_lhs_len = 3andtemp_rhs_len = 1and the parameterlhs_len = temp_lhs_len.- This means that instead of left shifting by 1 we shift by 3 to calculate the intersection.
- This is correct because the position of
t_2 t_3 t_4is the same ast_2and we need to intersect it with a token that is aftert_3andt_4.
- Second intersection:
t_2 t_3 t_4 t_5andt_6 t_7in this caselhs_len = temp_rhs_len(which is 1), we addtemp_rhs_lentotemp_lhs_len(temp_lhs_len += temp_rhs_len(which is 4)), and maketemp_rhs_len = 2(the length oft_6 t_7) (this will be used in the next intersection with the right token)- This is correct because after the first intersection the position of
t_2 t_3 t_4 t_5is the same ast_5and the position oft_6 t_7is the same ast_6.
- This is correct because after the first intersection the position of
- Third intersection:
t_0 t_1andt_2 t_3 t_4 t_5 t_6 t_7, at this pointtemp_lhs_len = 4so we add the length of the lhs token (2 in this case) makingtemp_lhs_len = 6and the parameterlhs_len = temp_lhs_len.- This is correct because the position of
t_0 t_1is the same ast_0andt_2 t_3 t_4 t_5 t_6 t_7has the same position ast_6(nott_7) (the position after intersecting with a token to the right is the position of the first token of the rhs sequence)
- This is correct because the position of
- Repeat this for the rest of the lhs and rhs tokens.
With this, I hope the lhs_len parameter makes sense. So why do we need it? We can just divide this value by 16 (remembering that each group holds 16 values) to find how much we need to add to the group of lhs to match rhs (remembering that the intersection is done in the 48 MSBs, document ID and group, so they need to be equal).
And the remainder of this division tells us how much we need to shift the lhs values (16 LSBs) to intersect with the rhs ones. We also use this remainder to calculate two bit masks msb_mask and lsb_mask (we will talk about them later). For example, if the remainder is 3, these masks will assume the following values (just keep them in mind):
msb_mask = 0b11100000 00000000lsb_mask = 0b00000000 00000111
Now we are ready to look at the naive intersection, yay!!
Naive Intersection
To more easily analyze the code of each intersection phase I will separate it into two fictitious functions, but in the final code, they are in the same function with the const generic flag.
First Phase
Here is the code for the first intersection phase:
const ADD_ONE_GROUP: u64 = u16::MAX as u64 + 1;
const fn clear_values(packed: u64) -> u64 {
packed & !0xFFFF
}
const fn unpack_values(packed: u64) -> u16 {
packed as u16
}
struct NaiveIntersect;
impl IntersectSeal for NaiveIntersect {}
impl Intersect for NaiveIntersect {
fn inner_intersect_first_phase(
lhs: BorrowRoaringishPacked<'_, Aligned>,
rhs: BorrowRoaringishPacked<'_, Aligned>,
lhs_i: &mut usize,
rhs_i: &mut usize,
packed_result: &mut Box<[MaybeUninit<u64>], Aligned64>,
i: &mut usize,
msb_packed_result: &mut Box<[MaybeUninit<u64>], Aligned64>,
j: &mut usize,
add_to_group: u64,
lhs_len: u16,
msb_mask: u16,
lsb_mask: u16,
) {
while *lhs_i < lhs.0.len() && *rhs_i < rhs.0.len() {
let lhs_packed = unsafe { *lhs.0.get_unchecked(*lhs_i) } + add_to_group;
let lhs_doc_id_group = clear_values(lhs_packed);
let lhs_values = unpack_values(lhs_packed);
let rhs_packed = unsafe { *rhs.0.get_unchecked(*rhs_i) };
let rhs_doc_id_group = clear_values(rhs_packed);
let rhs_values = unpack_values(rhs_packed);
match lhs_doc_id_group.cmp(&rhs_doc_id_group) {
std::cmp::Ordering::Equal => {
unsafe {
let intersection = (lhs_values << lhs_len) & rhs_values;
packed_result
.get_unchecked_mut(*i)
.write(lhs_doc_id_group | intersection as u64);
msb_packed_result
.get_unchecked_mut(*j)
.write(lhs_packed + ADD_ONE_GROUP);
*j += (lhs_values & msb_mask > 0) as usize;
}
*i += 1;
*lhs_i += 1;
*rhs_i += 1;
}
std::cmp::Ordering::Greater => *rhs_i += 1,
std::cmp::Ordering::Less => {
unsafe {
msb_packed_result
.get_unchecked_mut(*j)
.write(lhs_packed + ADD_ONE_GROUP);
*j += (lhs_values & msb_mask > 0) as usize;
}
*lhs_i += 1;
}
}
}
}
fn intersection_buffer_size(
lhs: BorrowRoaringishPacked<'_, Aligned>,
rhs: BorrowRoaringishPacked<'_, Aligned>,
) -> usize {
lhs.0.len().min(rhs.0.len())
}
}
The code itself is not that hard to understand, so let’s go through it.
Imagine this loop as the basic intersection algorithm for two sorted arrays (in our case, they are sorted from lowest to highest document ID and group). Like the conventional algorithm, we increment the index of lhs or rhs depending on which one is the smallest. If they are equal, advance both (1/3 of the function already explained, nice).
But in our case, as mentioned multiple times, the intersection is done with only the 48 MSBs. That’s why we call the function clear_values, so we use the document ID and group from the lhs (without forgetting to add to the group) and compare it with the rhs one (2/3 done).
And to finish, let’s analyze what we write into the output buffers (packed_result and msb_packed_result).
If lhs_doc_id_group == rhs_doc_id_group:
- We compute the intersection of the values (similar to how the original implementation of Doug does, but here we shift left by the remainder of the division).
- This intersection can be 0. We could check with an if statement or do it branchless, but we can also check this during the merge phase, and that’s what I decided to do (this makes our lives in the SIMD version easier).
- We could do two checks, one here and one in the merge, but there is no need/meaningful speed difference, so it’s fine.
- Write the OR between
lhs_doc_id_groupand theintersectiontopacked_result. - We also do a branchless write only if the bits of lhs value would cross the group boundary when shifting (that’s why we have the
msb_mask). To save the work in the second phase, we already add one to the group (themsb_packed_resultis used in the second intersection phase as the lhs one).
The operation described above of writing to msb_packed_result is repeated when incrementing the lhs index (the reason is that in the second phase, we need to analyze all possible cases where the bits would cross the group boundary) (3/3 done).
And with that, I hope now you know how the first phase of the naive intersection works.
Second Phase
Let’s analyze the second phase now. It will be easier this time since we already know how phase one works.
//...
fn inner_intersect_second_phase(
lhs: BorrowRoaringishPacked<'_, Aligned>,
rhs: BorrowRoaringishPacked<'_, Aligned>,
lhs_i: &mut usize,
rhs_i: &mut usize,
packed_result: &mut Box<[MaybeUninit<u64>], Aligned64>,
i: &mut usize,
msb_packed_result: &mut Box<[MaybeUninit<u64>], Aligned64>,
j: &mut usize,
add_to_group: u64,
lhs_len: u16,
msb_mask: u16,
lsb_mask: u16,
) {
while *lhs_i < lhs.0.len() && *rhs_i < rhs.0.len() {
let lhs_packed = unsafe { *lhs.0.get_unchecked(*lhs_i) };
let lhs_doc_id_group = clear_values(lhs_packed);
let lhs_values = unpack_values(lhs_packed);
let rhs_packed = unsafe { *rhs.0.get_unchecked(*rhs_i) };
let rhs_doc_id_group = clear_values(rhs_packed);
let rhs_values = unpack_values(rhs_packed);
match lhs_doc_id_group.cmp(&rhs_doc_id_group) {
std::cmp::Ordering::Equal => {
unsafe {
let intersection =
lhs_values.rotate_left(lhs_len as u32) & lsb_mask & rhs_values;
packed_result
.get_unchecked_mut(*i)
.write(lhs_doc_id_group | intersection as u64);
}
*i += 1;
*lhs_i += 1;
*rhs_i += 1;
}
std::cmp::Ordering::Greater => *rhs_i += 1,
std::cmp::Ordering::Less => *lhs_i += 1
}
}
}
//...
To reiterate, the lhs in this case is the msb_packed_result from the previous phase.
As you can see, they are very, very similar (that’s why I decided to use the const generic). There are a few changes:
- We don’t need to add a value to the lhs document ID and group (since we already did this in the previous phase).
- The way we compute the values intersection is different. Instead of shifting left, we do a rotate left (shifting where the bits wrap up to the other side), intersect it with the rhs values, and clean up with the
lsb_mask. - We don’t need to write to
msb_packed_result.
And this is the entirety of the intersection process, first and second phase.
Note: Having this approach of computing the mask and having an arbitrary value for the lhs token length solves the other problem discussed in the original article. Slop problem (yes, it’s called slop).
Note: You might have noticed a lot of unsafe get_unchecked operations. In this case, the compiler would probably be able to remove the bounds check, but I want to be sure, that’s why I’m doing it.
Code for the naive intersection merged into a single function (you can ignore if you want)
fn inner_intersect<const FIRST: bool>(
lhs: BorrowRoaringishPacked<'_, Aligned>,
rhs: BorrowRoaringishPacked<'_, Aligned>,
lhs_i: &mut usize,
rhs_i: &mut usize,
packed_result: &mut Box<[MaybeUninit<u64>], Aligned64>,
i: &mut usize,
msb_packed_result: &mut Box<[MaybeUninit<u64>], Aligned64>,
j: &mut usize,
add_to_group: u64,
lhs_len: u16,
msb_mask: u16,
lsb_mask: u16,
) {
while *lhs_i < lhs.0.len() && *rhs_i < rhs.0.len() {
let lhs_packed =
unsafe { *lhs.0.get_unchecked(*lhs_i) } + if FIRST { add_to_group } else { 0 };
let lhs_doc_id_group = clear_values(lhs_packed);
let lhs_values = unpack_values(lhs_packed);
let rhs_packed = unsafe { *rhs.0.get_unchecked(*rhs_i) };
let rhs_doc_id_group = clear_values(rhs_packed);
let rhs_values = unpack_values(rhs_packed);
match lhs_doc_id_group.cmp(&rhs_doc_id_group) {
std::cmp::Ordering::Equal => {
unsafe {
if FIRST {
let intersection = (lhs_values << lhs_len) & rhs_values;
packed_result
.get_unchecked_mut(*i)
.write(lhs_doc_id_group | intersection as u64);
msb_packed_result
.get_unchecked_mut(*j)
.write(lhs_packed + ADD_ONE_GROUP);
*j += (lhs_values & msb_mask > 0) as usize;
} else {
let intersection =
lhs_values.rotate_left(lhs_len as u32) & lsb_mask & rhs_values;
packed_result
.get_unchecked_mut(*i)
.write(lhs_doc_id_group | intersection as u64);
}
}
*i += 1;
*lhs_i += 1;
*rhs_i += 1;
}
std::cmp::Ordering::Greater => *rhs_i += 1,
std::cmp::Ordering::Less => {
if FIRST {
unsafe {
msb_packed_result
.get_unchecked_mut(*j)
.write(lhs_packed + ADD_ONE_GROUP);
*j += (lhs_values & msb_mask > 0) as usize;
}
}
*lhs_i += 1;
}
}
}
}
And let the unholy SIMD begin…
All hail the king (or queen IDK) VP2INTERSECT
Is it just me, or does everyone have a favorite SIMD instruction? Let me introduce you to my favorite AVX-512 instruction.
By the name, you might guess what it does, right? And if I had to guess, you probably didn’t know that this instruction existed.
Why? You might ask, because sadly this is a deprecated instruction by Intel. If you are a chip engineer at AMD or Intel, please don’t deprecate this instruction, it has its use cases, trust me. Imagine when you guys release a new CPU and someone creates a benchmark that uses this instruction, wouldn’t your CPU look beautiful when compared to the competition?
I’m serious, don’t deprecate this instruction…
Ok, so how does this instruction work? In our case, we are interested in the 64-bit, 8-wide version, so here is the assembly for it:
vp2intersectq k, zmm, zmm
The fun thing about this little fella is that, unlike other instructions, it generates two masks, so it will clobber an additional register that is not specified in the operands, in this case, (kn+1).
Note: k registers are mask registers.
So let’s do an example to fully grasp the power of this instruction:
zmm0: 0 | 0 | 3 | 2 | 3 | 8 | 9 | 1
zmm1: 9 | 5 | 3 | 0 | 7 | 7 | 7 | 7
----------------------------------------
k2 (zmm0): 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0
k3 (zmm1): 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0
What is being computed is the intersection of the register zmm0 and zmm1, but we check every number against every other number. So if the output mask has 1 in the position, it means that the value was present somewhere in the other register.
Note: Just to be 100% clear, the k2 mask refers to the zmm0 register and k3 to zmm1.
Basically, a for loop inside a for loop. Here is the Intel intrinsic guide:
There are several weird things about this instruction, and that’s why a lot of people hate it, but that’s what makes it charming. One of its weird quirks is that it generates two masks, but in 99.9% of the cases when computing the intersection, you only want/need one. But in our use case, having one mask for each register is essential.
Wanna know something funny?
As far as I know, this instruction is only present in two CPU generations:
- Tiger Lake (11th gen Mobile CPUs)
Zen 5(Spoiler)
And coincidentally, my notebook has an 11th gen CPU, lucky… When I started this project, I didn’t know about this instruction, so it’s pure luck.
Wanna hear another funny thing?
This instruction sucks on 11th gen… I mean truly, in every sense of the word.
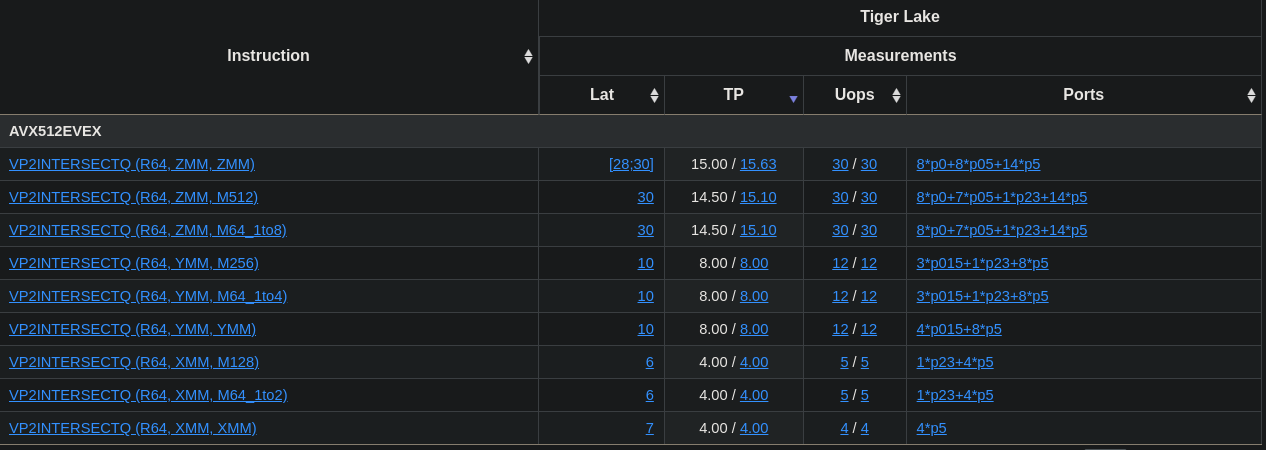
Table is taken from uops.info.
Our mnemonic is the first one in the list, let’s go through the stats.
- Latency: 30 cycles
- Throughput: 15 cycles
- Uops: 30
If you don’t know that much about CPUs, trust me, this is bad… It’s so bad that this gigachad (Guille Díez-Canãs) made an emulated version that is faster…
So now do you trust me that it’s bad?
This emulated version isn’t a strict emulation, because as I said earlier, in 99.9% of use cases, you only need one mask. So when emulated for generating a single mask, this instruction can be made faster by using other instructions!!!!
Here is the compiler explorer link for both of them if you are intrested.
Here is the throughput predicted by uiCA for each version:
-
Native version
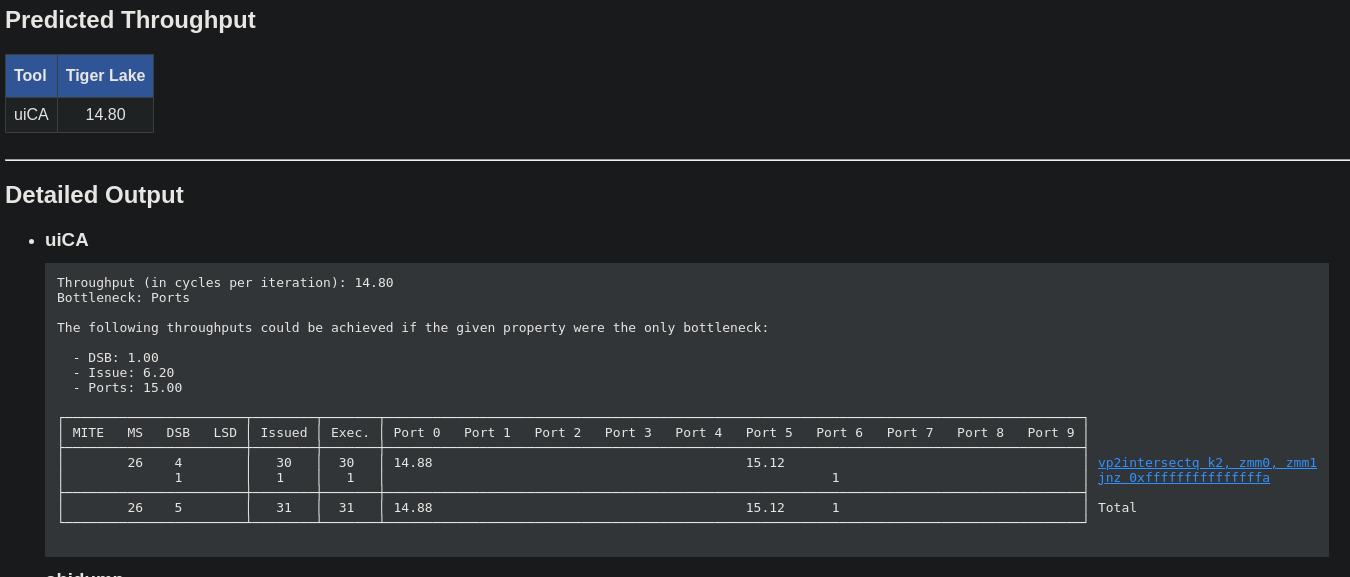
-
Single mask emulation
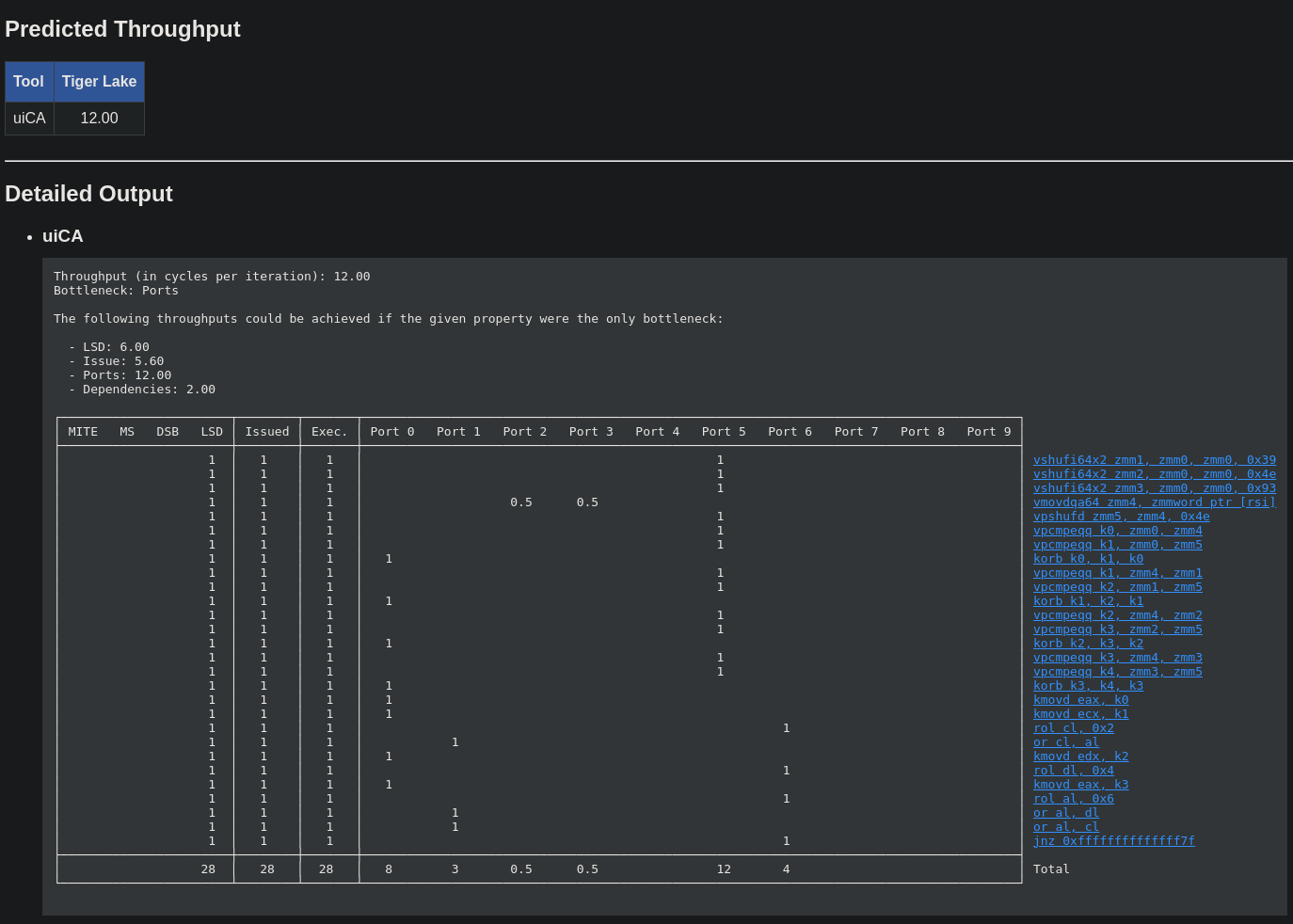
-
Strict emulation
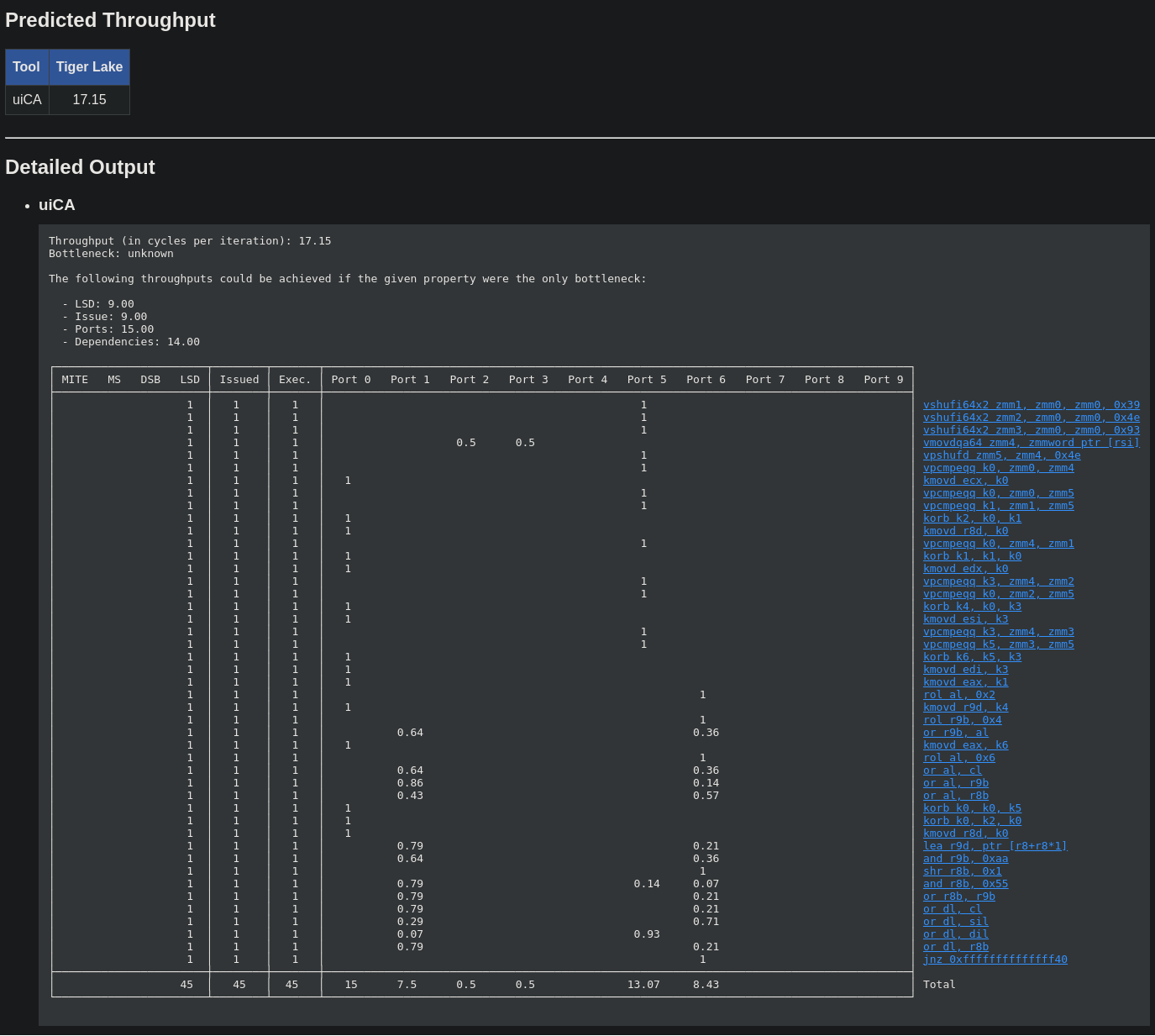
As you can see, the author of the paper is not lying… So yeah, it’s bad…
Even though it sucks, nothing else on this CPU can compute the intersection of two vectors faster, so it’s still the fastest way to get what we want.
If you haven’t laughed in the last two sections, now I will make you cry while laughing
It wasn’t enough for me to get lucky and have a chip that is capable of using this (rare) instruction. Our lord and savior AMD had to release the second CPU lineup (Zen 5) in the world that supports this instruction while I was developing this project.
So luck is definitely on my side.
I didn’t pay much attention to it, but when I read this article I couldn’t hold my wallet anymore and had to get a Zen 5 chip:
So just as Intel kills off VP2INTERSECT, AMD shows up with it. Needless to say, Zen5 had
probably already taped out by the time Intel deprecated the instruction. So VP2INTERSECT
made it into Zen5's design and wasn't going to be removed.
But how good is AMD's implementation? Let's look at AIDA64's dumps for Granite Ridge:
AVX512VL_VP2INTERSE :VP2INTERSECTD k1+1, xmm, xmm L: [diff. reg. set] T: 0.23ns= 1.00c
AVX512VL_VP2INTERSE :VP2INTERSECTD k1+1, ymm, ymm L: [diff. reg. set] T: 0.23ns= 1.00c
AVX512_VP2INTERSECT :VP2INTERSECTD k1+1, zmm, zmm L: [diff. reg. set] T: 0.23ns= 1.00c
AVX512VL_VP2INTERSE :VP2INTERSECTQ k1+1, xmm, xmm L: [diff. reg. set] T: 0.23ns= 1.00c
AVX512VL_VP2INTERSE :VP2INTERSECTQ k1+1, ymm, ymm L: [diff. reg. set] T: 0.23ns= 1.00c
AVX512_VP2INTERSECT :VP2INTERSECTQ k1+1, zmm, zmm L: [diff. reg. set] T: 0.23ns= 1.00c
Yes, that's right. 1 cycle throughput. ONE cycle. I can't... I just can't...
You read this right, this beauty is 15x faster on AMD… 15 f* times. WOW…
So yeah, I got a Zen 5 chip… Capitalism wins again.
Don’t let reviewers tell you that this generation is bad, that the 9700x is a bad chip, and so on… If you need an AVX-512 compatible CPU, go get yourself a Zen 5 chip, they are monstrous.
Just to be 100% sure that chip engineers understood my message, DON’T KILL THIS INSTRUCTION !!!
Note: After switching to the 9700x I didn’t experience a 15x improvement and that was/is expected. The hot loop consists of other operations (as you will see), so in reality, I got 2-5x depending on the query. Pretty good win IMHO.
Compress/Compress Store
This is the last piece of the puzzle for us to understand the SIMD version. Compress and Compress Store are also CPU instructions and they are very similar.
The difference is that Compress will write to a register and Compress Store to memory.
By the name, it’s fairly easy to tell that they are compressing something, but what exactly? They basically receive a register and mask and pack the values from the register if the bit is set in the mask.
zmm0: 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7
k1: 1 | 1 | 0 | 0 | 1 | 0 | 0 | 1
-----------------------------------
0 | 1 | 4 | 7 | X | X | X | X
And X can be specified, or can be 0 if you want. Pretty dope, right?
Here are the mnemonics:
vpcompressq zmm {z}, zmm
vpcompressq zmm {k}, zmm
vpcompressq m64 {k}, zmm
Note: Compress Store is super slow on Zen 4, so people usually do Compress + Store, which was way faster. I thought they fixed it on Zen 5 (the article I shared earlier also says that it is better), but at least in my benchmarks, doing a Compress + Store is still faster in Zen 5, not by much but a little. I haven’t micro-benchmarked the instruction, just changed it in my use case and measured the impact, that is why you are going to see Compress + Store.
With this, we are ready to understand the SIMD version.
SIMD Intersection
Similar to the naive version, I will split each phase and we will analyze them separately (there will be a diagram at the end showing how things work with a drawing).
Note: This is the place where I spent the most time, I easily rewrote this 20 times trying to save every cycle possible.
First Phase
const N: usize = 8;
const fn clear_values(packed: u64) -> u64 {
packed & !0xFFFF
}
#[inline(always)]
fn clear_values_simd<const N: usize>(packed: Simd<u64, N>) -> Simd<u64, N>
where
LaneCount<N>: SupportedLaneCount,
{
packed & Simd::splat(!0xFFFF)
}
#[inline(always)]
fn unpack_values_simd<const N: usize>(packed: Simd<u64, N>) -> Simd<u64, N>
where
LaneCount<N>: SupportedLaneCount,
{
packed & Simd::splat(0xFFFF)
}
#[inline(always)]
unsafe fn vp2intersectq(a: __m512i, b: __m512i) -> (u8, u8) {
use std::arch::x86_64::__mmask8;
let mut mask0: __mmask8;
let mut mask1: __mmask8;
asm!(
"vp2intersectq k2, {0}, {1}",
in(zmm_reg) a,
in(zmm_reg) b,
out("k2") mask0,
out("k3") mask1,
options(pure, nomem, nostack),
);
(mask0, mask1)
}
#[inline(always)]
unsafe fn analyze_msb(
lhs_pack: Simd<u64, N>,
msb_packed_result: &mut [MaybeUninit<u64>],
j: &mut usize,
msb_mask: Simd<u64, N>,
) {
let mask = (lhs_pack & msb_mask).simd_gt(Simd::splat(0)).to_bitmask() as u8;
let pack_plus_one: Simd<u64, N> = lhs_pack + Simd::splat(ADD_ONE_GROUP);
unsafe {
let compress = _mm512_maskz_compress_epi64(mask, pack_plus_one.into());
_mm512_storeu_epi64(msb_packed_result.as_mut_ptr().add(*j) as *mut _, compress);
}
*j += mask.count_ones() as usize;
}
struct SimdIntersect;
impl IntersectSeal for SimdIntersect {}
impl Intersect for SimdIntersect {
#[inline(always)]
fn inner_intersect_first_phase(
lhs: BorrowRoaringishPacked<'_, Aligned>,
rhs: BorrowRoaringishPacked<'_, Aligned>,
lhs_i: &mut usize,
rhs_i: &mut usize,
packed_result: &mut Box<[MaybeUninit<u64>], Aligned64>,
i: &mut usize,
msb_packed_result: &mut Box<[MaybeUninit<u64>], Aligned64>,
j: &mut usize,
add_to_group: u64,
lhs_len: u16,
msb_mask: u16,
lsb_mask: u16,
) {
let simd_msb_mask = Simd::splat(msb_mask as u64);
let simd_lsb_mask = Simd::splat(lsb_mask as u64);
let simd_add_to_group = Simd::splat(add_to_group);
let end_lhs = lhs.0.len() / N * N;
let end_rhs = rhs.0.len() / N * N;
let lhs_packed = unsafe { lhs.0.get_unchecked(..end_lhs) };
let rhs_packed = unsafe { rhs.0.get_unchecked(..end_rhs) };
assert_eq!(lhs_packed.len() % N, 0);
assert_eq!(rhs_packed.len() % N, 0);
let mut need_to_analyze_msb = false;
while *lhs_i < lhs_packed.len() && *rhs_i < rhs_packed.len() {
let lhs_last =
unsafe { clear_values(*lhs_packed.get_unchecked(*lhs_i + N - 1)) + add_to_group };
let rhs_last = unsafe { clear_values(*rhs_packed.get_unchecked(*rhs_i + N - 1)) };
let (lhs_pack, rhs_pack): (Simd<u64, N>, Simd<u64, N>) = unsafe {
let lhs_pack = _mm512_load_epi64(lhs_packed.as_ptr().add(*lhs_i) as *const _);
let rhs_pack = _mm512_load_epi64(rhs_packed.as_ptr().add(*rhs_i) as *const _);
(lhs_pack.into(), rhs_pack.into())
};
let lhs_pack = lhs_pack + simd_add_to_group;
let lhs_doc_id_group = clear_values_simd(lhs_pack);
let rhs_doc_id_group = clear_values_simd(rhs_pack);
let rhs_values = unpack_values_simd(rhs_pack);
let (lhs_mask, rhs_mask) =
unsafe { vp2intersectq(lhs_doc_id_group.into(), rhs_doc_id_group.into()) };
unsafe {
let lhs_pack_compress: Simd<u64, N> =
_mm512_maskz_compress_epi64(lhs_mask, lhs_pack.into()).into();
let doc_id_group_compress = clear_values_simd(lhs_pack_compress);
let lhs_values_compress = unpack_values_simd(lhs_pack_compress);
let rhs_values_compress: Simd<u64, N> =
_mm512_maskz_compress_epi64(rhs_mask, rhs_values.into()).into();
let intersection =
(lhs_values_compress << (lhs_len as u64)) & rhs_values_compress;
_mm512_storeu_epi64(
packed_result.as_mut_ptr().add(*i) as *mut _,
(doc_id_group_compress | intersection).into(),
);
*i += lhs_mask.count_ones() as usize;
}
if lhs_last <= rhs_last {
unsafe {
analyze_msb(lhs_pack, msb_packed_result, j, simd_msb_mask);
}
*lhs_i += N;
}
*rhs_i += N * (rhs_last <= lhs_last) as usize;
need_to_analyze_msb = rhs_last < lhs_last;
}
if need_to_analyze_msb && !(*lhs_i < lhs.0.len() && *rhs_i < rhs.0.len()) {
unsafe {
let lhs_pack: Simd<u64, N> =
_mm512_load_epi64(lhs_packed.as_ptr().add(*lhs_i) as *const _).into();
analyze_msb(
lhs_pack + simd_add_to_group,
msb_packed_result,
j,
simd_msb_mask,
);
};
}
NaiveIntersect::inner_intersect_first_phase(
lhs,
rhs,
lhs_i,
rhs_i,
packed_result,
i,
msb_packed_result,
j,
add_to_group,
lhs_len,
msb_mask,
lsb_mask,
);
}
fn intersection_buffer_size(
lhs: BorrowRoaringishPacked<'_, Aligned>,
rhs: BorrowRoaringishPacked<'_, Aligned>,
) -> usize {
lhs.0.len().min(rhs.0.len()) + 1 + N
}
}
It’s a lot of code, but it’s not hard, I swear. It’s very similar to the naive version. So let’s begin:
Before the main loop begins, we initialize the SIMD version of the needed variables by splatting, and also since SIMD works N = 8 elements wide, we need to cap the lhs and rhs Roaringish Packed vector to the closest multiple of N.
Loop over this capped slice, so instead of incrementing by 1 the lhs or rhs index, we increment by N (similar to the naive version).
- Get the last lhs and rhs document ID and group of the current SIMD vector. This is used at the end of the loop to check which index we need to increment by
N(similar to the naive version).
Note: There is a very specific reason for this to be at the beginning of the loop and not at the end where they are used. We will get there, just wait.
- Load the
Nelements from lhs and rhs (similar to the naive version).
Note: If you know your SIMD intrinsics, you will notice that this is an aligned load. Doing aligned loads is considerably faster, that’s why we want things to be 64-byte aligned, to get a speedup here. I know that using the unaligned version will lead to the same performance if the address happens to be aligned, but I want to be 100% sure that we are doing aligned loads because if not, something went wrong, and I prefer to crash the program if this happens.
-
Add to the group of the lhs vector and get the document ID and group from lhs and rhs. We also get the values from rhs (similar to the naive version).
-
Intersect the lhs and rhs document ID and group (similar to the naive version) using the beautiful vp2intersect and get their respective masks back.
Note: Since all document IDs and groups in lhs/rhs are different (in increasing order), we know that the number of bits set in each mask is the same.
Note: If lhs_mask is 0, consequently rhs_mask will also be 0. We could introduce a branch here and skip the whole unsafe block I’m about to describe, but doing it unconditionally is faster for the first phase (probably hard for the branch predictor), but in the second phase, as you will see, there is a branch, and in that case, it helps a lot (probably because it’s easier for the branch predictor to know that it is ok to skip the workload).
- Use the lhs mask to compress the lhs packed (fill with 0 the rest), get the document ID and group from this compressed version, and also get the values.
Note: It’s faster to do a Compress followed by 2 ands than to do one additional and in the beginning to get the values from the packed version and do 2 Compress, one for the document ID and group and another for the values.
- Compress the rhs values using the rhs mask.
Note: At this point, we know that the values of the document ID and groups that are in the intersection are next to each other in the SIMD lanes.
-
Calculate the intersection of the lhs and rhs values (similar to the naive version).
-
Store the OR between
doc_id_group_compress(this comes from lhs) andintersectionintopacked_result(similar to the naive version).
Note: I couldn’t find a way to eliminate this unaligned store, unfortunately. From what I measured with perf, this is now one of the big bottlenecks of this loop.
- Increment
i(similar to the naive version) (length ofpacked_result) by the number of document IDs and groups that were in the intersection and have their values intersection computed (this will generate a popcount).
Note: That’s why I said that allowing the values intersection to be 0 makes our life easier. If not, we would need to check which values in the intersection vector are greater than 0 and do one more Compress operation, not good… Checking this during the merge phase is faster and cleaner, in my opinion.
- Do a branchless increment of the rhs index, but we need to do a branch to analyze the values from lhs that have MSBs set.
Note: Doing a branch here is fine. It’s not the most predictable, but it’s faster than doing it unconditionally.
-
AND the values from lhs with the
msb_maskand get a mask of which values have the MSBs set. -
Add one to the lhs document ID and group from lhs (similar to the naive version).
-
Store to
msb_packed_resultthe lanes that have the MSBs set using the mask, by doing a Compress + Store.
Note: That’s where I measured the poor performance of Compress Store in my use case. Changing here to Compress + Store made things faster.
- Increment
jby the number of elements written tomsb_packed_result(this will generate a popcount).
After the loop ends by incrementing the rhs index and we are still in bounds for the non-capped slice, we need to do one last analysis on the lhs values MSBs. Because if not, we might skip one potential candidate for the second phase.
Similar to every SIMD algorithm, we need to finish it off by doing a scalar version, so we reuse the naive version by calling it.
Note: This will be very fast since at this point there are 7 or fewer elements in lhs or rhs.
I hope all of this made sense. It’s very similar to the naive version in various points. The only esoteric things we need to do are related to vp2intersect and Compress/Compress Store/Compress + Store.
Here is a diagram of one iteration of the loop. I hope this helps (let’s use the syntax document ID,group,values to avoid having to write binary).
// let's assume this values
add_to_group: 1
lhs_len: 1
lhs_packed: ... | 1,0,v_0 | 1,1,v_1 | 5,0,v_2 | 5,2,v_3 | 5,3,v_4 | 6,2,v_5 | 7,0,v_6 | 8,1,v_7 | ...
^
lhs_i
rhs_packed: ... | 1,1,v_8 | 2,0,v_9 | 5,3,v_10| 5,5,v_11| 6,1,v_12| 9,0,v_13| 9,1,v_14| 9,2,v_15| ...
^
rhs_i
lhs_last: 8,2,v_7 (already added add_to_group)
lhs_last: 9,2,v_15
lhs_pack: 1,1,v_0 | 1,2,v_1 | 5,1,v_2 | 5,3,v_3 | 5,4,v_4 | 6,3,v_5 | 7,1,v_6 | 8,2,v_7 (already added add_to_group)
rhs_pack: 1,1,v_8 | 2,0,v_9 | 5,3,v_10| 5,5,v_11| 6,1,v_12| 9,0,v_13| 9,1,v_14| 9,2,v_15
lhs_doc_id_group: 1,1,0 | 1,2,0 | 5,1,0 | 5,3,0 | 5,4,0 | 6,3,0 | 7,1,0 | 8,2,0
rhs_doc_id_group: 1,1,0 | 2,0,0 | 5,3,0 | 5,5,0 | 6,1,0 | 9,0,0 | 9,1,0 | 9,2,0
rhs_values: 0,0,v_8 | 0,0,v_9 | 0,0,v_10| 0,0,v_11| 0,0,v_12| 0,0,v_13| 0,0,v_14| 0,0,v_15
// Calculate the vp2intersect of lhs_doc_id_group and rhs_doc_id_group
lhs_mask: 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 (0b10010000)
rhs_mask 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 (0b10100000)
// Compress operation of lhs_pack and lhs_mask
1,1,v_0 | 1,2,v_1 | 5,1,v_2 | 5,3,v_3 | 5,4,v_4 | 6,3,v_5 | 7,1,v_6 | 8,2,v_7
1 | 0 | 0 | 1 | 0 | 0 | 0 | 0
lhs_pack_compress: 1,1,v_0 | 5,3,v_3 | 0,0,0 | 0,0,0 | 0,0,0 | 0,0,0 | 0,0,0 | 0,0,0
doc_id_group_compress: 1,1,0 | 5,3,0 | 0,0,0 | 0,0,0 | 0,0,0 | 0,0,0 | 0,0,0 | 0,0,0
lhs_values_compress: 0,0,v_0 | 0,0,v_3 | 0,0,0 | 0,0,0 | 0,0,0 | 0,0,0 | 0,0,0 | 0,0,0
// Compress operation of rhs_values and rhs_mask
0,0,v_8 | 0,0,v_9 | 0,0,v_10| 0,0,v_11| 0,0,v_12| 0,0,v_13| 0,0,v_14| 0,0,v_15
1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
rhs_values_compress: 0,0,v_8 | 0,0,v_10| 0,0,0 | 0,0,0 | 0,0,0 | 0,0,0 | 0,0,0 | 0,0,0
// Bitwise intersection between lhs_values_compress and rhs_values_compress
// (I'm going to ignore the document ID an group, since they are 0
// to make it fit on screen, but they are still there)
intersection: (v_0 << 1)&v_8 | (v_3 << 1)&v_10 | (0 << 1)&0 | (0 << 1)&0 | (0 << 1)&0 | (0 << 1)&0 | (0 << 1)&0 | (0 << 1)&0
// Simplifying
intersection: (v_0 << 1)&v_8 | (v_3 << 1)&v_10 | 0 | 0 | 0 | 0 | 0 | 0
// Store into packed_result (lhs_values_compress | intersection)
packed_result: ... | 1,1,(v_0 << 1)&v_8 | 5,3,(v_3 << 1)&v_10 | 0,0,0 | 0,0,0 | 0,0,0 | 0,0,0 | 0,0,0 | 0,0,0
^
i
// i is incremented by 2, since there is 2 bits in lhs_mask (0b10010000)
i: i + 2
// Now i points here when the next iteration starts
packed_result: ... | 1,1,(v_0 << 1)&v_8 | 5,3,(v_3 << 1)&v_10 | 0,0,0 | 0,0,0 | 0,0,0 | 0,0,0 | 0,0,0 | 0,0,0
^
i
// Since lhs_last <= rhs_last we need to analyze the MSBs
// msb_mask is 64bit x 8 lanes, but the 16LSB's is where this value can
// change (because this is where the values are poisitioned), so the
// 48 MSBs are zeroed out.
// (lhs_pack & msb_mask) > 0
// I'm going to randomly generete some bits for the mask for the sake
// of the example
mask: 0 | 1 | 1 | 0 | 1 | 0 | 1 | 0 (0b01101010)
// lhs_pack + ADD_ONE_GROUP
pack_plus_one 1,2,v_0 | 1,3,v_1 | 5,2,v_2 | 5,4,v_3 | 5,5,v_4 | 6,4,v_5 | 7,2,v_6 | 8,3,v_7
// Compress of pack_plus_one and mask
1,2,v_0 | 1,3,v_1 | 5,2,v_2 | 5,4,v_3 | 5,5,v_4 | 6,4,v_5 | 7,2,v_6 | 8,3,v_7
0 | 1 | 1 | 0 | 1 | 0 | 1 | 0
compress: 1,3,v_1 | 5,2,v_2 | 5,5,v_4 | 7,2,v_6 | 0,0,0 | 0,0,0 | 0,0,0 | 0,0,0
// Store into msb_packed_result
msb_packed_result: ... | 1,3,v_1 | 5,2,v_2 | 5,5,v_4 | 7,2,v_6 | 0,0,0 | 0,0,0 | 0,0,0 | 0,0,0 | ...
^
j
// j is incremented by 4, since there is 4 bits in mask (0b01101010)
j: j + 4
// Now j points here when the next iteration starts
msb_packed_result: ... | 1,3,v_1 | 5,2,v_2 | 5,5,v_4 | 7,2,v_6 | 0,0,0 | 0,0,0 | 0,0,0 | 0,0,0 | ...
^
j
// Since lhs_last <= rhs_last
lhs_i: lhs_i + N (N = 8)
rhs_i: rhs_i
need_to_analyze_msb: false
And that’s one full iteration of the loop. I know it seems like a lot, but it’s not. There are a bunch of numbers on the screen, but most of the operations are very simple, so I hope you can understand it.
Second Phase
Similar to the naive version, analyzing the second phase will be easier, so here is the code:
#[inline(always)]
fn rotl_u16(a: Simd<u64, N>, i: u64) -> Simd<u64, N> {
let p0 = a << i;
let p1 = a >> (16 - i);
// we don't need to unpack the values, since
// in the next step we already `and` with
// with mask where the doc ID and group are
// zeroed
p0 | p1
}
#[inline(always)]
fn inner_intersect_second_phase<const FIRST: bool>(
lhs: BorrowRoaringishPacked<'_, Aligned>,
rhs: BorrowRoaringishPacked<'_, Aligned>,
lhs_i: &mut usize,
rhs_i: &mut usize,
packed_result: &mut Box<[MaybeUninit<u64>], Aligned64>,
i: &mut usize,
msb_packed_result: &mut Box<[MaybeUninit<u64>], Aligned64>,
j: &mut usize,
add_to_group: u64,
lhs_len: u16,
msb_mask: u16,
lsb_mask: u16,
) {
let simd_msb_mask = Simd::splat(msb_mask as u64);
let simd_lsb_mask = Simd::splat(lsb_mask as u64);
let simd_add_to_group = Simd::splat(add_to_group);
let end_lhs = lhs.0.len() / N * N;
let end_rhs = rhs.0.len() / N * N;
let lhs_packed = unsafe { lhs.0.get_unchecked(..end_lhs) };
let rhs_packed = unsafe { rhs.0.get_unchecked(..end_rhs) };
assert_eq!(lhs_packed.len() % N, 0);
assert_eq!(rhs_packed.len() % N, 0);
while *lhs_i < lhs_packed.len() && *rhs_i < rhs_packed.len() {
let lhs_last = unsafe { clear_values(*lhs_packed.get_unchecked(*lhs_i + N - 1)) };
let rhs_last = unsafe { clear_values(*rhs_packed.get_unchecked(*rhs_i + N - 1)) };
let (lhs_pack, rhs_pack): (Simd<u64, N>, Simd<u64, N>) = unsafe {
let lhs_pack = _mm512_load_epi64(lhs_packed.as_ptr().add(*lhs_i) as *const _);
let rhs_pack = _mm512_load_epi64(rhs_packed.as_ptr().add(*rhs_i) as *const _);
(lhs_pack.into(), rhs_pack.into())
};
let lhs_doc_id_group = clear_values_simd(lhs_pack);
let rhs_doc_id_group = clear_values_simd(rhs_pack);
let rhs_values = unpack_values_simd(rhs_pack);
let (lhs_mask, rhs_mask) =
unsafe { vp2intersectq(lhs_doc_id_group.into(), rhs_doc_id_group.into()) };
if lhs_mask > 0 {
unsafe {
let lhs_pack_compress: Simd<u64, N> =
_mm512_maskz_compress_epi64(lhs_mask, lhs_pack.into()).into();
let doc_id_group_compress = clear_values_simd(lhs_pack_compress);
let lhs_values_compress = unpack_values_simd(lhs_pack_compress);
let rhs_values_compress: Simd<u64, N> =
_mm512_maskz_compress_epi64(rhs_mask, rhs_values.into()).into();
let intersection =
rotl_u16(lhs_values_compress, lhs_len as u64)
& simd_lsb_mask
& rhs_values_compress;
_mm512_storeu_epi64(
packed_result.as_mut_ptr().add(*i) as *mut _,
(doc_id_group_compress | intersection).into(),
);
*i += lhs_mask.count_ones() as usize;
}
}
*lhs_i += N * (lhs_last <= rhs_last) as usize;
*rhs_i += N * (rhs_last <= lhs_last) as usize;
need_to_analyze_msb = rhs_last < lhs_last;
}
NaiveIntersect::inner_intersect_second_phase(
lhs,
rhs,
lhs_i,
rhs_i,
packed_result,
i,
msb_packed_result,
j,
add_to_group,
lhs_len,
msb_mask,
lsb_mask,
);
}
I hope you can see that the first phase and the second phase are very similar, and also the second phase from the SIMD version and naive version are also very similar (just like the first phase).
There are a few noticeable differences:
- Just like in the naive version, we don’t need to add the value of
add_to_groupsince it has already been done in the first phase. - We introduce an
if lhs_mask > 0to make the code faster, as mentioned earlier. - The way we compute the values intersection is very similar to the naive version: rotate to the left,
andwithlsb_mask, andrhs_values.
Note: If you look closely, the rotl_u16 function receives u64x8, but we are only interested in rotating the 16 LSBs (values bits), so that’s why I can use something like _mm512_rol_epi64.
- In the second phase, we don’t need to analyze the values that have the MSBs set, so there is no branch. Instead, we do a branchless increment of
lhs_i, just like we did withrhs_i.
And that’s it, that’s how you implement an intersection using AVX-512.
Code for the SIMD intersection merged into a single function (you can ignore if you want)
#[inline(always)]
fn inner_intersect<const FIRST: bool>(
lhs: BorrowRoaringishPacked<'_, Aligned>,
rhs: BorrowRoaringishPacked<'_, Aligned>,
lhs_i: &mut usize,
rhs_i: &mut usize,
packed_result: &mut Box<[MaybeUninit<u64>], Aligned64>,
i: &mut usize,
msb_packed_result: &mut Box<[MaybeUninit<u64>], Aligned64>,
j: &mut usize,
add_to_group: u64,
lhs_len: u16,
msb_mask: u16,
lsb_mask: u16,
) {
let simd_msb_mask = Simd::splat(msb_mask as u64);
let simd_lsb_mask = Simd::splat(lsb_mask as u64);
let simd_add_to_group = Simd::splat(add_to_group);
let end_lhs = lhs.0.len() / N * N;
let end_rhs = rhs.0.len() / N * N;
let lhs_packed = unsafe { lhs.0.get_unchecked(..end_lhs) };
let rhs_packed = unsafe { rhs.0.get_unchecked(..end_rhs) };
assert_eq!(lhs_packed.len() % N, 0);
assert_eq!(rhs_packed.len() % N, 0);
let mut need_to_analyze_msb = false;
while *lhs_i < lhs_packed.len() && *rhs_i < rhs_packed.len() {
let lhs_last = unsafe {
clear_values(*lhs_packed.get_unchecked(*lhs_i + N - 1))
+ if FIRST { add_to_group } else { 0 }
};
let rhs_last = unsafe { clear_values(*rhs_packed.get_unchecked(*rhs_i + N - 1)) };
let (lhs_pack, rhs_pack): (Simd<u64, N>, Simd<u64, N>) = unsafe {
let lhs_pack = _mm512_load_epi64(lhs_packed.as_ptr().add(*lhs_i) as *const _);
let rhs_pack = _mm512_load_epi64(rhs_packed.as_ptr().add(*rhs_i) as *const _);
(lhs_pack.into(), rhs_pack.into())
};
let lhs_pack = if FIRST {
lhs_pack + simd_add_to_group
} else {
lhs_pack
};
let lhs_doc_id_group = clear_values_simd(lhs_pack);
let rhs_doc_id_group = clear_values_simd(rhs_pack);
let rhs_values = unpack_values_simd(rhs_pack);
let (lhs_mask, rhs_mask) =
unsafe { vp2intersectq(lhs_doc_id_group.into(), rhs_doc_id_group.into()) };
if FIRST || lhs_mask > 0 {
unsafe {
let lhs_pack_compress: Simd<u64, N> =
_mm512_maskz_compress_epi64(lhs_mask, lhs_pack.into()).into();
let doc_id_group_compress = clear_values_simd(lhs_pack_compress);
let lhs_values_compress = unpack_values_simd(lhs_pack_compress);
let rhs_values_compress: Simd<u64, N> =
_mm512_maskz_compress_epi64(rhs_mask, rhs_values.into()).into();
let intersection = if FIRST {
(lhs_values_compress << (lhs_len as u64)) & rhs_values_compress
} else {
rotl_u16(lhs_values_compress, lhs_len as u64)
& simd_lsb_mask
& rhs_values_compress
};
_mm512_storeu_epi64(
packed_result.as_mut_ptr().add(*i) as *mut _,
(doc_id_group_compress | intersection).into(),
);
*i += lhs_mask.count_ones() as usize;
}
}
if FIRST {
if lhs_last <= rhs_last {
unsafe {
analyze_msb(lhs_pack, msb_packed_result, j, simd_msb_mask);
}
*lhs_i += N;
}
} else {
*lhs_i += N * (lhs_last <= rhs_last) as usize;
}
*rhs_i += N * (rhs_last <= lhs_last) as usize;
need_to_analyze_msb = rhs_last < lhs_last;
}
if FIRST && need_to_analyze_msb && !(*lhs_i < lhs.0.len() && *rhs_i < rhs.0.len()) {
unsafe {
let lhs_pack: Simd<u64, N> =
_mm512_load_epi64(lhs_packed.as_ptr().add(*lhs_i) as *const _).into();
analyze_msb(
lhs_pack + simd_add_to_group,
msb_packed_result,
j,
simd_msb_mask,
);
};
}
NaiveIntersect::inner_intersect::<FIRST>(
lhs,
rhs,
lhs_i,
rhs_i,
packed_result,
i,
msb_packed_result,
j,
add_to_group,
lhs_len,
msb_mask,
lsb_mask,
);
}
Never trust the compiler
What I’m about to tell you doesn’t happen in the current version, but it happened in a previous one. I swear I’m not going crazy…
Do you remember earlier when I said that there is a very specific reason why the lhs_last and rhs_last are loaded at the beginning of the loop but only used at the end?
Like any normal and sane person, I wrote code like this:
/// let's say we are in the first phase
while *lhs_i < lhs.0.len() && *rhs_i < rhs.0.len() {
// no human beign would put this at the
// beginning of the loop, far away
// from where it's being used
// let lhs_last =
// unsafe { clear_values(*lhs_packed.get_unchecked(*lhs_i + N - 1)) + add_to_group };
// let rhs_last = unsafe { clear_values(*rhs_packed.get_unchecked(*rhs_i + N - 1)) };
// ...
// any sane person would put this here
// close to where it's used
let lhs_last =
unsafe { clear_values(*lhs_packed.get_unchecked(*lhs_i + N - 1)) + add_to_group };
let rhs_last = unsafe { clear_values(*rhs_packed.get_unchecked(*rhs_i + N - 1)) };
if lhs_last <= rhs_last {
unsafe {
analyze_msb(lhs_pack, msb_packed_result, j, simd_msb_mask);
}
*lhs_i += N;
}
*rhs_i += N * (rhs_last <= lhs_last) as usize;
need_to_analyze_msb = rhs_last < lhs_last;
}
But here is the sad thing, LLVM is dumb (or too smart, IDK). You would hope that the generated assembly would be the same for both cases. I’m literally only moving two lines of code up and down (they are not used anywhere previously in the loop).
The version where the lhs_last and rhs_last are loaded at the end made the code generation way worse.
Here is the compiler explorer link of an older version of the intersect function (you don’t need to understand what is going on, just that in the first version they are loaded at the end and in the second they are loaded at the beginning).
I took a print from the diff of the important assembly section (left: loaded at the end | right: loaded at the beginning):
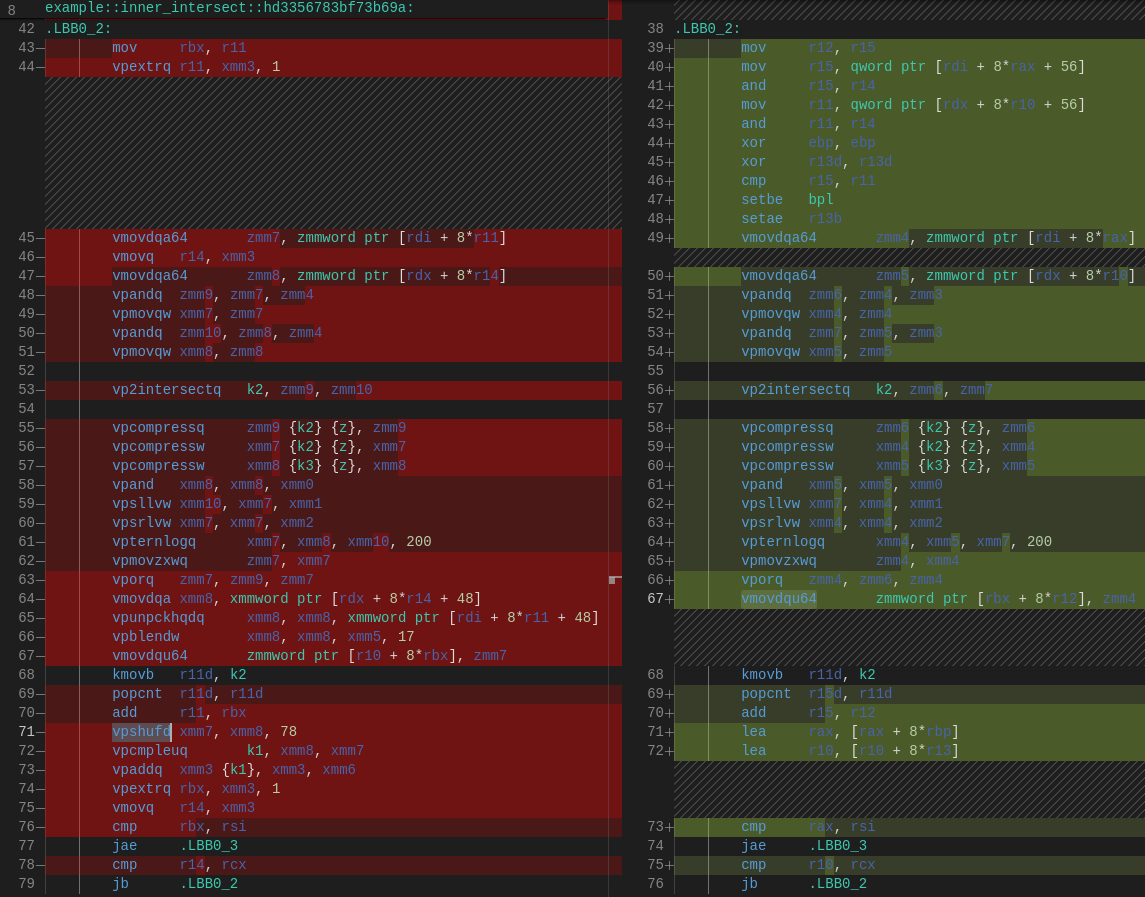
I don’t have 20/20 vision, but they look different to me…
So what is the problem? There are a few, but mainly with these instructions:
;...
vpunpckhqdq xmm8, xmm8, xmmword ptr [rdi + 8*r11 + 48]
vpblendw xmm8, xmm8, xmm5, 17
;...
vpshufd xmm7, xmm8, 78
vpcmpleuq k1, xmm8, xmm7
vpaddq xmm3 {k1}, xmm3, xmm6
vpextrq rbx, xmm3, 1
vmovq r14, xmm3
The compiler is trying to be smart and optimize the loads by doing some SIMD shenanigans. I’m no LLVM specialist, so reading LLVM IR and LLVM optimization passes to me is like reading a foreign language, so I can’t be 100% sure why it’s trying to do this. But if I had to guess, it’s that since the last values are already loaded by lhs_pack and rhs_pack, it tries to use them instead of loading again.
Unfortunately, this leads to horrible performance loss, since it’s way faster to do 2 movs followed by 2 leas (just like in the version where they are loaded at the beginning of the loop).
I would assume that by loading them at the beginning (before loading the vectors), it removes the possibility or makes it harder for the compiler to optimize.
As mentioned: The current version doesn’t suffer from this issue, and since the function changed a lot from this version to the current one, only God knows what changed in the LLVM optimization pipeline to avoid this problem. So to be 100% sure that this will not happen in the future when I change the intersection code, I will leave it at the beginning of the loop.
Assembly analysis
Let’s take a look at the assembly generated for the hot loop in the first phase.
.LBB23_19:
mov rdi, qword ptr [rsp + 72]
vmovdqa64 zmm8, zmmword ptr [rdi + 8*r14]
mov rsi, qword ptr [rdi + 8*r14 + 56]
and rsi, rdx
add rsi, rbx
vpaddq zmm7, zmm8, zmm1
vpandq zmm9, zmm7, zmm3
.p2align 4, 0x90
.LBB23_20:
vmovdqa64 zmm10, zmmword ptr [r15 + 8*rbp]
mov r9, qword ptr [rsp + 48]
mov rdi, qword ptr [r15 + 8*rbp + 56]
mov r8, r12
and rdi, rdx
vpandq zmm11, zmm10, zmm4
vp2intersectq k2, zmm9, zmm11
vpcompressq zmm11 {k2} {z}, zmm7
vpandq zmm10, zmm10, zmm5
vpcompressq zmm10 {k3} {z}, zmm10
vpandq zmm12, zmm11, zmm5
vpsllvq zmm12, zmm12, zmm2
vpandq zmm10, zmm12, zmm10
vpternlogq zmm10, zmm11, zmm4, 248
vmovdqu64 zmmword ptr [r9 + 8*r12], zmm10
kmovb r12d, k2
popcnt r12d, r12d
add r12, r8
cmp rsi, rdi
jbe .LBB23_25
add rbp, 8
cmp rbp, rcx
jb .LBB23_20
jmp .LBB23_22
.p2align 4, 0x90
.LBB23_25:
vptestmq k1, zmm8, zmm0
vpaddq zmm7, zmm7, zmm6
mov r8, qword ptr [rsp + 8]
add r14, 8
vpcompressq zmm7 {k1} {z}, zmm7
vmovdqu64 zmmword ptr [r8 + 8*r13], zmm7
kmovb r8d, k1
popcnt r8d, r8d
add r13, r8
xor r8d, r8d
cmp rdi, rsi
setbe r8b
lea rbp, [rbp + 8*r8]
cmp r14, rax
jae .LBB23_27
cmp rbp, rcx
jb .LBB23_19
Look at all those zmm registers, sexy right? Let’s run this through uiCA (for Tiger Lake) and see how fast we can theoretically go.
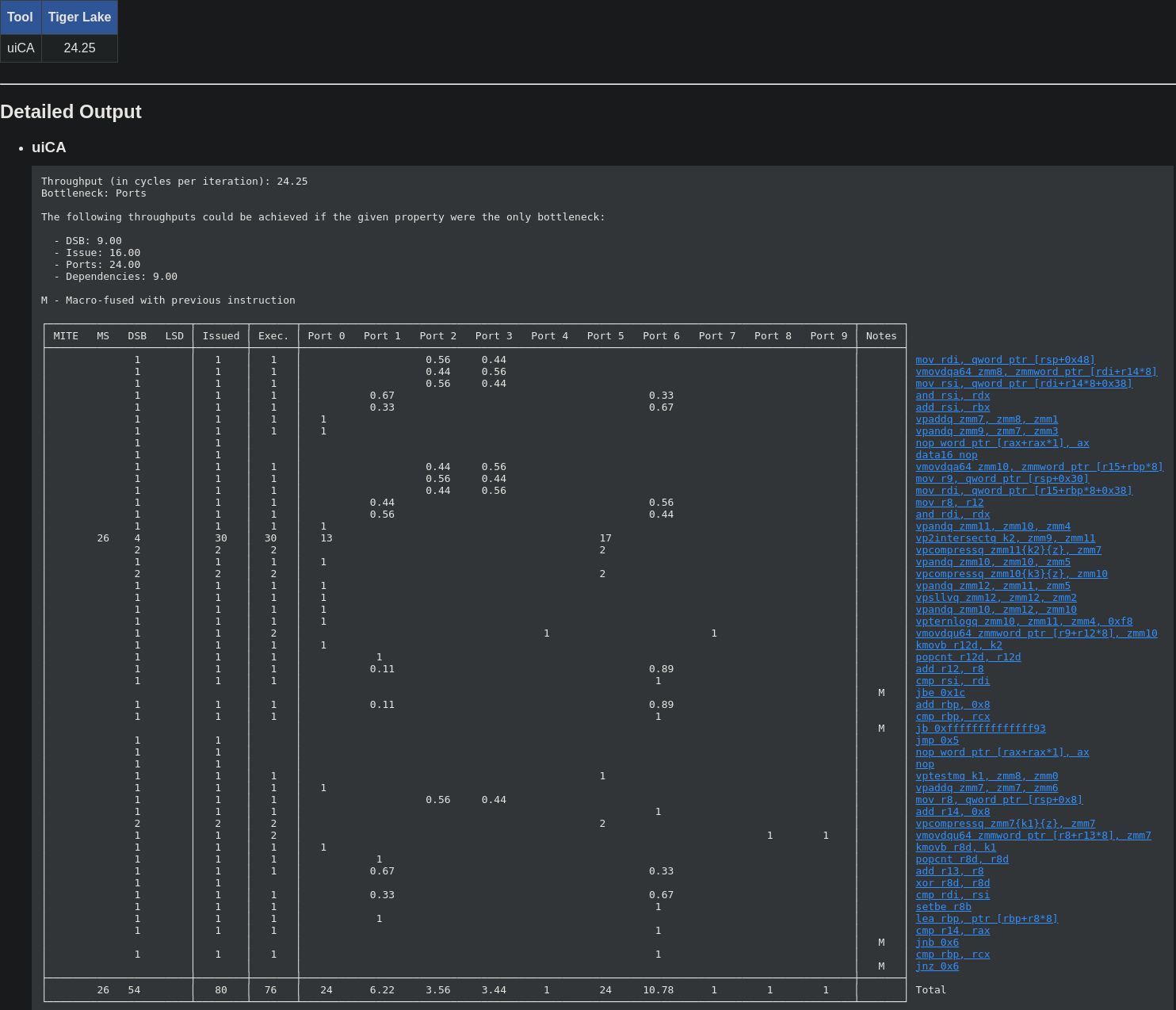
Note: I know uiCA and tools similar to it like llvm-mca are just a simulation of the best-case scenario. In the real world, this number is way higher, but it’s good enough for us to analyze the behavior of the code.
24 cycles / 8 elements (3 cycles / element) is pretty decent IMHO, and that’s for Tiger Lake. On Zen 5, this value is probably lower.
Just for fun, let’s do some napkin math and figure out an approximation for it on my 9700x system. The values were taken from one of the queries that have two tokens after merging.
Note: As I said in the disclaimer, the time taken is pretty damn consistent between runs.
lhs len: 551280
rhs len: 3728037
Since this is O(n+m): 551280 + 3728037 = 4279317 elements
The loop it self runs 534556 times, so we analyze: 534556 × 8 = 4276448 elements
Difference: 4279317 - 4276448 = 2869 elements (we are going through almost all elements)
CPU runs at 5.4Ghz
There is 1000000 us in 1 s: 1000000 ÷ 54000000000 = 0.000018519 us/cycle
First phase for this query takes 849.331us (Spoiler): 849.331 / 0.000018519 = 45862681 cycles
45862681 / 4276448 = 10.72 cycles/element
And that’s the effect of caches and branch prediction for you. The values in real life will always be higher than the theoretical best scenario. But still, pretty good.
Note: Here is a great article for you if you want to go at the speed limit.
Code alignment
During the development lifecycle, sometimes I would make a change somewhere in the codebase that wasn’t the intersection code, and this would impact the performance of things, especially for the second phase.
I would measure a degradation of up to 50%, but why? The generated assembly is the same, and I didn’t even change the code. WTF? And that’s when you learn that the memory addresses of your functions and loops matter.
Note: Great article about this topic.
So what is the problem? The generated assembly for the loop in the second phase has 173 bytes, and this fits into 3 cache lines (each one of 64 bytes). So depending on where it’s placed, it would cross a cache line and make it use 4 instead of 3, resulting in slower execution.
To analyze this problem, I developed a tool that shows you the alignment of code (I couldn’t find one online, so…).
Here is the output when the code is unaligned:

As you can see, we are using 4 cache lines. Fixing this is easy and hard at the same time.
The easy part is that we only need to introduce some nops before the code segment to align it to the beginning of the cache line.
The hard thing is that the number of nops will change if the generated code changes. So a new compiler version, targeting another CPU/using different features, or changing the code will make this number go up and down…
Also, functions are 16-byte aligned by default on the ELF spec, so even if we add the correct number of nops, just recompiling the code after a small change in another part of the source code (far away from the intersection function) can mess up the number of nops.
So that’s an unwinnable fight. One way to mitigate the problem with the ELF alignment of functions is to forcefully align them to 64 bytes. This can be done by using the flag -C llvm-args=-align-all-functions=6. This will ensure that at least the number of nops doesn’t change if you modify the code somewhere else (of course, you need to #[inline(never)] the function).
So with that in mind, I compiled all of my code with -C llvm-args=-align-all-functions=6 and found the number of nops needed in each phase.
if FIRST {
for _ in 0..26 {
unsafe {
asm!("nop");
}
}
} else {
for _ in 0..48 {
unsafe {
asm!("nop");
}
}
}

And that’s the output you want to see, the beginning of the loop on a 64-byte boundary.
The last optimization ideas
Binary Search
One simple but effective idea to reduce the number of intersections is to binary search lhs or rhs depending on which has the smallest first document ID by the first document ID from the other. Doing so allows us to skip the beginning section of the Roaringish Packed.
This idea is especially effective in scenarios like this:
lhs: 1000000,g_0,v_0 | ...
rhs: ... (imagine a bunch of elements here) | 1000000,g_1,v_1 | ...
We are going to search by 1000000,0,0
Skipping all of the beginning section of rhs avoids having to compute the intersection of elements that can’t be in the final result.
We have to be careful though, for this to work properly we need to search for only the document ID, the group, and values need to be 0, so we find the first occurrence of this document ID, avoiding skipping elements where the value MSBs would cross the group boundary.
Also, take care to align the beginning of the Roaringish Packed to 64 bytes.
Code for the binary search (you can ignore if you want)
fn binary_search(
lhs: &mut BorrowRoaringishPacked<'_, Aligned>,
rhs: &mut BorrowRoaringishPacked<'_, Aligned>,
) {
let Some(first_lhs) = lhs.0.first() else {
return;
};
let Some(first_rhs) = rhs.0.first() else {
return;
};
let first_lhs = clear_group_values(*first_lhs);
let first_rhs = clear_group_values(*first_rhs);
match first_lhs.cmp(&first_rhs) {
std::cmp::Ordering::Less => {
let i = match lhs.0.binary_search_by_key(&first_rhs, |p| clear_values(*p)) {
Ok(i) => i,
Err(i) => i,
};
let aligned_i = i / 8 * 8;
*lhs = BorrowRoaringishPacked::new_raw(&lhs.0[aligned_i..]);
}
std::cmp::Ordering::Greater => {
let i = match rhs.0.binary_search_by_key(&first_lhs, |p| clear_values(*p)) {
Ok(i) => i,
Err(i) => i,
};
let aligned_i = i / 8 * 8;
*rhs = BorrowRoaringishPacked::new_raw(&rhs.0[aligned_i..]);
}
std::cmp::Ordering::Equal => {}
}
}
Gallop Intersection
And we have come full circle… In the second article, Doug described how using this intersection helped speed up SearchArray. So let’s use it to our advantage.
When computing intersections where the number of elements in lhs is way smaller than in rhs (or vice-versa), we can use gallop intersection instead of the SIMD intersection and get a significant speedup. In my testing, I found that it’s worth switching to gallop intersection when one of the sides is 650x bigger than the other in the first phase and 120x in the second phase.
const FIRST_GALLOP_INTERSECT: usize = 650;
const SECOND_GALLOP_INTERSECT: usize = 120;
//...
let proportion = lhs
.len()
.max(rhs.len())
.checked_div(lhs.len().min(rhs.len()));
let Some(proportion) = proportion else {
return RoaringishPacked::default();
};
if proportion >= FIRST_GALLOP_INTERSECT {
let (packed, _) = GallopIntersectFirst::intersect::<true>(lhs, rhs, lhs_len);
let (msb_packed, _) =
GallopIntersectFirst::intersect::<false>(lhs, rhs, lhs_len);
return Self::merge_results(packed, msb_packed);
}
let (packed, msb_packed) = I::intersect::<true>(lhs, rhs, lhs_len);
//...
let proportion = msb_packed
.len()
.max(rhs.len())
.checked_div(msb_packed.len().min(rhs.len()));
let (msb_packed, _) = match proportion {
Some(proportion) => {
if proportion >= SECOND_GALLOP_INTERSECT {
GallopIntersectSecond::intersect::<false>(msb_packed, rhs, lhs_len)
} else {
I::intersect::<false>(msb_packed, rhs, lhs_len)
}
}
None => I::intersect::<false>(msb_packed, rhs, lhs_len),
};
The way that the gallop intersection works is different from the naive and SIMD versions. Since we are skipping elements, we can’t accumulate all of the elements that have the values MSBs set to use in a second phase. Instead, we need to use the original Roaringish Packed and modify the second phase to account for this. That’s why we have GallopIntersectFirst, which has two phases, and GallopIntersectSecond, which has only one phase (the second one).
I will not bother you with the details. If you want to look at how they are implemented, here is the code.
Code for GallopIntersectFirst (you can ignore if you want)
pub struct GallopIntersectFirst;
impl Intersect for GallopIntersectFirst {
fn inner_intersect<const FIRST: bool>(
lhs: BorrowRoaringishPacked<'_, Aligned>,
rhs: BorrowRoaringishPacked<'_, Aligned>,
lhs_i: &mut usize,
rhs_i: &mut usize,
packed_result: &mut Box<[MaybeUninit<u64>], Aligned64>,
i: &mut usize,
_msb_packed_result: &mut Box<[MaybeUninit<u64>], Aligned64>,
_j: &mut usize,
add_to_group: u64,
lhs_len: u16,
_msb_mask: u16,
lsb_mask: u16,
) {
while *lhs_i < lhs.len() && *rhs_i < rhs.len() {
let mut lhs_delta = 1;
let mut rhs_delta = 1;
while *lhs_i < lhs.len()
&& clear_values(lhs[*lhs_i]) + add_to_group + if FIRST { 0 } else { ADD_ONE_GROUP }
< clear_values(rhs[*rhs_i])
{
*lhs_i += lhs_delta;
lhs_delta *= 2;
}
*lhs_i -= lhs_delta / 2;
while *rhs_i < rhs.len()
&& clear_values(rhs[*rhs_i])
< unsafe { clear_values(*lhs.get_unchecked(*lhs_i)) }
+ add_to_group
+ if FIRST { 0 } else { ADD_ONE_GROUP }
{
*rhs_i += rhs_delta;
rhs_delta *= 2;
}
*rhs_i -= rhs_delta / 2;
let lhs_packed = unsafe { *lhs.get_unchecked(*lhs_i) }
+ add_to_group
+ if FIRST { 0 } else { ADD_ONE_GROUP };
let rhs_packed = unsafe { *rhs.get_unchecked(*rhs_i) };
let lhs_doc_id_group = clear_values(lhs_packed);
let rhs_doc_id_group = clear_values(rhs_packed);
let lhs_values = unpack_values(lhs_packed);
let rhs_values = unpack_values(rhs_packed);
match lhs_doc_id_group.cmp(&rhs_doc_id_group) {
std::cmp::Ordering::Less => *lhs_i += 1,
std::cmp::Ordering::Greater => *rhs_i += 1,
std::cmp::Ordering::Equal => {
let intersection = if FIRST {
(lhs_values << lhs_len) & rhs_values
} else {
lhs_values.rotate_left(lhs_len as u32) & lsb_mask & rhs_values
};
unsafe {
packed_result
.get_unchecked_mut(*i)
.write(lhs_doc_id_group | intersection as u64);
}
*i += (intersection > 0) as usize;
*lhs_i += 1;
*rhs_i += 1;
}
}
}
}
}
Code for GallopIntersectSecond (you can ignore if you want)
pub struct GallopIntersectSecond;
impl Intersect for GallopIntersectSecond {
fn inner_intersect<const FIRST: bool>(
lhs: BorrowRoaringishPacked<'_, Aligned>,
rhs: BorrowRoaringishPacked<'_, Aligned>,
lhs_i: &mut usize,
rhs_i: &mut usize,
packed_result: &mut Box<[MaybeUninit<u64>], Aligned64>,
i: &mut usize,
_msb_packed_result: &mut Box<[MaybeUninit<u64>], Aligned64>,
_j: &mut usize,
_add_to_group: u64,
lhs_len: u16,
_msb_mask: u16,
lsb_mask: u16,
) {
while *lhs_i < lhs.len() && *rhs_i < rhs.len() {
let mut lhs_delta = 1;
let mut rhs_delta = 1;
while *lhs_i < lhs.len() && clear_values(lhs[*lhs_i]) < clear_values(rhs[*rhs_i]) {
*lhs_i += lhs_delta;
lhs_delta *= 2;
}
*lhs_i -= lhs_delta / 2;
while *rhs_i < rhs.len()
&& clear_values(rhs[*rhs_i]) < unsafe { clear_values(*lhs.get_unchecked(*lhs_i)) }
{
*rhs_i += rhs_delta;
rhs_delta *= 2;
}
*rhs_i -= rhs_delta / 2;
let lhs_packed = unsafe { *lhs.get_unchecked(*lhs_i) };
let rhs_packed = unsafe { *rhs.get_unchecked(*rhs_i) };
let lhs_doc_id_group = clear_values(lhs_packed);
let rhs_doc_id_group = clear_values(rhs_packed);
let lhs_values = unpack_values(lhs_packed);
let rhs_values = unpack_values(rhs_packed);
match lhs_doc_id_group.cmp(&rhs_doc_id_group) {
std::cmp::Ordering::Less => *lhs_i += 1,
std::cmp::Ordering::Greater => *rhs_i += 1,
std::cmp::Ordering::Equal => {
let intersection =
lhs_values.rotate_left(lhs_len as u32) & lsb_mask & rhs_values;
unsafe {
packed_result
.get_unchecked_mut(*i)
.write(lhs_doc_id_group | intersection as u64);
}
*i += (intersection > 0) as usize;
*lhs_i += 1;
*rhs_i += 1;
}
}
}
}
}
One funny thing is that when micro-benchmarking these functions, I found that doing branchless version is faster, but when used in the “real world,” the branching version is faster. I don’t know why and didn’t want to investigate…
Merging the phases
Not that interesting/anything going on. If you understood the article, I hope you can imagine how this would work.
Code for the merge (you can ignore if you want)
fn merge_results(
packed: Vec<u64, Aligned64>,
msb_packed: Vec<u64, Aligned64>,
) -> RoaringishPacked {
let capacity = packed.len() + msb_packed.len();
let mut r_packed = Box::new_uninit_slice_in(capacity, Aligned64::default());
let mut r_i = 0;
let mut j = 0;
for pack in packed.iter().copied() {
unsafe {
let doc_id_group = clear_values(pack);
let values = unpack_values(pack);
while j < msb_packed.len() {
let msb_pack = *msb_packed.get_unchecked(j);
let msb_doc_id_group = clear_values(msb_pack);
let msb_values = unpack_values(msb_pack);
j += 1;
if msb_doc_id_group >= doc_id_group {
j -= 1;
break;
}
if msb_values > 0 {
r_packed.get_unchecked_mut(r_i).write(msb_pack);
r_i += 1;
}
}
let write = values > 0;
if write {
r_packed.get_unchecked_mut(r_i).write(pack);
r_i += 1;
}
{
if j >= msb_packed.len() {
continue;
}
let msb_pack = *msb_packed.get_unchecked(j);
let msb_doc_id_group = clear_values(msb_pack);
let msb_values = unpack_values(msb_pack);
j += 1;
if msb_doc_id_group != doc_id_group {
j -= 1;
continue;
}
if write {
// in this case no bit was set in the intersection,
// so we can just `or` the new value with the previous one
let r = r_packed.get_unchecked_mut(r_i - 1).assume_init_mut();
*r |= msb_values as u64;
} else if msb_values > 0 {
r_packed.get_unchecked_mut(r_i).write(msb_pack);
r_i += 1;
}
}
}
}
for msb_pack in msb_packed.iter().skip(j).copied() {
unsafe {
let msb_values = unpack_values(msb_pack);
if msb_values > 0 {
r_packed.get_unchecked_mut(r_i).write(msb_pack);
r_i += 1;
}
}
}
unsafe {
let (p_packed, a0) = Box::into_raw_with_allocator(r_packed);
let packed = Vec::from_raw_parts_in(p_packed as *mut _, r_i, capacity, a0);
RoaringishPacked(packed)
}
}
Getting the document IDs
There is something interesting here, but the article is long enough, so I will just drop the naive and SIMD versions. They are very simple to understand, so if you want…
Code for the naive version (you can ignore if you want)
fn get_doc_ids(&self,) -> Vec<u32> {
if self.0.is_empty() {
return Vec::new();
}
if self.0.len() == 1 {
return vec![unpack_doc_id(self.0[0])];
}
let mut doc_ids: Box<[MaybeUninit<u32>]> = Box::new_uninit_slice(self.0.len());
let mut i = 0;
for [packed0, packed1] in self.0.array_windows::<2>() {
let doc_id0 = unpack_doc_id(*packed0);
let doc_id1 = unpack_doc_id(*packed1);
if doc_id0 != doc_id1 {
unsafe { doc_ids.get_unchecked_mut(i).write(doc_id0) };
i += 1;
}
}
unsafe {
doc_ids
.get_unchecked_mut(i)
.write(unpack_doc_id(*self.0.last().unwrap_unchecked()))
};
i += 1;
unsafe { Vec::from_raw_parts(Box::into_raw(doc_ids) as *mut _, i, self.0.len()) }
}
Code for the SIMD version (you can ignore if you want)
fn get_doc_ids(&self) -> Vec<u32> {
if self.0.is_empty() {
return Vec::new();
}
if self.0.len() == 1 {
return vec![unpack_doc_id(self.0[0])];
}
let mut doc_ids: Box<[MaybeUninit<u32>]> = Box::new_uninit_slice(self.0.len());
let mut i = 0;
unsafe { doc_ids.get_unchecked_mut(i).write(unpack_doc_id(self.0[0])) };
i += 1;
let mut last_doc_id = unpack_doc_id(self.0[0]);
let (l, m, r) = self.0.as_simd::<8>();
assert!(l.is_empty());
for packed in m {
let doc_id = unpack_doc_id_simd(*packed);
let rot = doc_id.rotate_elements_right::<1>();
let first = doc_id.as_array()[0];
let last = doc_id.as_array()[7];
let include_first = (first != last_doc_id) as u8;
let mask = (doc_id.simd_ne(rot).to_bitmask() as u8 & !1) | include_first;
unsafe {
_mm256_mask_compressstoreu_epi32(
doc_ids.as_mut_ptr().add(i) as *mut _,
mask,
doc_id.into(),
);
}
i += mask.count_ones() as usize;
last_doc_id = last;
}
let j = r
.iter()
.take_while(|packed| unpack_doc_id(**packed) == last_doc_id)
.count();
let r = &r[j..];
for [packed0, packed1] in r.array_windows::<2>() {
let doc_id0 = unpack_doc_id(*packed0);
let doc_id1 = unpack_doc_id(*packed1);
if doc_id0 != doc_id1 {
unsafe { doc_ids.get_unchecked_mut(i).write(doc_id0) };
i += 1;
}
}
if !r.is_empty() {
unsafe {
doc_ids
.get_unchecked_mut(i)
.write(unpack_doc_id(*r.last().unwrap_unchecked()))
};
i += 1;
}
unsafe { Vec::from_raw_parts(Box::into_raw(doc_ids) as *mut _, i, self.0.len()) }
}
And with that, we have covered all I wanted to talk about. I hope that everything made sense.
About Meilisearch
I’m not trying to dunk on Meilisearch, please don’t interpret it that way. The reason why I chose it is because it’s known for its good performance, ease of use, and my knowledge of how the internals work.
Since Meilisearch is a fully-fledged search engine, it wouldn’t be fair to use the final time, given it’s doing a lot more. This includes processing my query, JSON encoding/decoding, network operations (even though I’m running locally)… So to be fair, we will say that the time spent on the query itself is 80% of the total time (i.e 20% of the time was spent on Meilisearch internals). IMHO, this is very reasonable.
Note: 80% might even be too little. If I had to guess, it’s something around 95-98%, but to be fair, let’s use a lower number.
I used the latest version of Meilisearch available on nixpkgs (1.11.3) at the time of writing.
AFAIK, the Meilisearch implementation of phrase search works by computing the distance from every token to every other token (link 1, link 2), which is very time-consuming during indexing and takes a lot of disk space. I might be completely wrong, but that’s what I understood from looking at the code.
To be fair, my version indexes everything, so I didn’t change a single configuration on Meilisearch about stop words, but I changed the pagination maxTotalHits to 3.5 million (since there are 3.2 million documents).
Here are some stats about the Meilisearch index:

I have a single index with the contents leading to a total size of almost 300GB (15x write amplification, since the original corpus is 20GB).
Looking at the size of the database responsible for saving data about phrase search, we have a whopping 864 million entries in it.

When compared to my version the index size is only 74GB (of course Meilisearch index needs to be bigger, because it’s doing a lot more).
Results
So how is this going to work: I have a list of 53 different queries with different bottlenecks. I will run the naive and SIMD versions and also index the same data on Meilisearch, search the same queries, and compare all of them. In the end, I will group the queries in tables representing their bottlenecks.
You can hover over queries that are collapsed with ellipsis to see the whole content.
Note: Just as a disclaimer because this can be confusing. The normalization and tokenization of the text are done with the unicode-segmentation crate, and the way it deals with punctuation is a bit weird. Tokenizing "google.com" will result in ["google.com"], which is the inverse of what you would expect, which is ["google", ".", "com"], but tokenizing "google. com" will result in ["google", ".", "com"]. So the case where https://google found 0 results and https://google.com found 14 is correct.
Note: You might notice that Meilisearch returns more results, and there are a few reasons for it:
- The way it deals with punctuation is different. In my version, punctuation is like any other token, but for Meilisearch, it becomes a space.
- It also returns documents with subqueries of the searched query. For example, the query
may have significant health effectsreturns 3 documents containing this sequence (just like mine), but also returns one additional document containingmay have significant immunomodulatory effects.
Note: I think I found a bug in the Meilisearch implementation where it doesn’t properly scape phrases containing quotes in it. So if you notice phrases like "help" or "Science News from... have way more results returned by Meilisearch than expected. I don’t think I have made a mistake, for example here is the payload I sent when searching by "help".
{
"q":"\"\\\"help\\\"\"",
"hitsPerPage":10
}
As you can see I have prorperly scaped the quotes inside the phrase it self, so take with a grain of salt the results for this queries. Even though the phrase search algorithm is faster than their default keyword search.
All times are measured in ms.
Simd/Naive Intersection
These are queries mainly bottlenecked by computing the intersection using the SIMD or naive algorithms. Here is where we are going to see the performance difference between them.
| Query | Simd | Naive | Meilisearch | Meilisearch (Original) | Results | Results (Meilisearch) | Performance gain |
|---|---|---|---|---|---|---|---|
| programming languages | 0.1496 | 0.7454 | 3.3945 | 4.2432 | 3284 | 3489 | 22.6905x |
| you need to be | 1.7760 | 9.3750 | 2.7952 | 3.4939 | 16144 | 49635 | 1.5739x |
| chemistry lessons | 0.1017 | 0.5944 | 1.8531 | 2.3164 | 38 | 42 | 18.2212x |
| how to file taxes | 0.4956 | 2.1627 | 1.2569 | 1.5712 | 32 | 69 | 2.5361x |
| how to make money | 2.0469 | 10.2508 | 2.3632 | 2.9540 | 779 | 1250 | 1.1545x |
| and you are in the most | 0.0266 | 0.1630 | 11.8306 | 14.7882 | 0 | 3318 | 444.7594x |
| as well as our | 0.3715 | 1.1343 | 6.2618 | 7.8273 | 2031 | 2151 | 16.8555x |
| you should go to the | 0.2172 | 1.3700 | 11.7778 | 14.7223 | 564 | 1236 | 54.2256x |
| do you know ? | 0.1869 | 0.8600 | 1.4690 | 1.8362 | 1054 | 33626 | 7.8598x |
| http:// | 2.1016 | 5.7091 | 1.3640 | 1.7050 | 280110 | 292613 | 0.6490x |
| if i was to give you | 0.1602 | 1.2111 | 30.1017 | 37.6271 | 3 | 61 | 187.9007x |
| may have significant health effects | 0.4302 | 3.2684 | 2.0546 | 2.5682 | 3 | 4 | 4.7759x |
| where are you going | 0.0168 | 0.0295 | 1.5833 | 1.9792 | 602 | 842 | 94.2440x |
| but refused to join in | 0.0358 | 0.1139 | 2.7975 | 3.4969 | 2 | 2 | 78.1425x |
| it may be useful to | 5.9048 | 13.7519 | 3.8842 | 4.8553 | 961 | 1487 | 0.6578x |
| A logical step before choosing the metrics and activities | 0.0228 | 0.0806 | 0.7340 | 0.9175 | 1 | 1 | 32.1930x |
| of American Universities | 0.0854 | 0.6251 | 3.0246 | 3.7807 | 244 | 299 | 35.4169x |
| beta-plus decay, it changes | 0.0107 | 0.0176 | 2.4970 | 3.1212 | 1 | 5 | 233.3645x |
| https://google | 0.0932 | 0.2599 | 2.5573 | 3.1966 | 0 | 20 | 27.4388x |
| However, some argue that it has less taste | 0.0483 | 0.2504 | 0.8314 | 1.0393 | 1 | 1 | 17.2133x |
| It is important not to | 0.2090 | 1.4102 | 3.5816 | 4.4769 | 1564 | 2102 | 17.1368x |
| Windows 10 | 1.6637 | 7.5760 | 1.5102 | 1.8877 | 11264 | 11479 | 0.9077x |
| knowledge base article | 0.6087 | 3.3039 | 1.2739 | 1.5924 | 440 | 470 | 2.0928x |
| is common in | 14.0448 | 32.1616 | 3.6056 | 4.5070 | 10134 | 13558 | 0.2567x |
| this is common in | 0.5524 | 2.3168 | 7.3389 | 9.1737 | 522 | 796 | 13.2855x |
| this is common in the | 0.5166 | 1.3803 | 9.9872 | 12.4840 | 57 | 216 | 19.3326x |
| and is thought to be | 0.2677 | 1.1394 | 8.6885 | 10.8606 | 673 | 1364 | 32.4561x |
| , you need to make sure that you have | 0.7306 | 2.6941 | 8.1053 | 10.1316 | 29 | 1050 | 11.0940x |
| we hope you had a great time | 0.1882 | 0.8915 | 4.4113 | 5.5141 | 4 | 9 | 23.4394x |
| phrase search | 0.2445 | 1.3501 | 1.6172 | 2.0215 | 9 | 19 | 6.6143x |
Simd/Naive + Gallop
Queries where they are equally bounded by computing the SIMD/naive intersection and computing the gallop intersection.
| Query | Simd | Naive | Meilisearch | Meilisearch (Original) | Results | Results (Meilisearch) | Performance gain |
|---|---|---|---|---|---|---|---|
| 1 2 3 | 1.6561 | 4.4241 | 2.3420 | 2.9275 | 42095 | 80286 | 1.4142x |
| 1 2 3 4 5 6 7 | 4.9899 | 14.1061 | 6.8714 | 8.5893 | 9630 | 13114 | 1.3771x |
| when did this happen | 0.1744 | 0.5298 | 7.4109 | 9.2637 | 49 | 52 | 42.4937x |
| World War II was fought | 0.0213 | 0.0721 | 3.4111 | 4.2638 | 18 | 23 | 160.1455x |
| is common in the | 2.5428 | 9.2461 | 6.5425 | 8.1781 | 1549 | 3876 | 2.5730x |
Gallop Intersection
These are queries where gallop intersection dominates, so the difference between naive and SIMD is very close (most of the difference is due to noise).
| Query | Simd | Naive | Meilisearch | Meilisearch (Original) | Results | Results (Meilisearch) | Performance gain |
|---|---|---|---|---|---|---|---|
| "”help”” | 0.5473 | 0.5428 | 1.1099 | 1.3874 | 913 | 972623 | 2.0280x |
| "”help” | 0.6309 | 0.6298 | 1.1167 | 1.3959 | 913 | 972623 | 1.7700x |
| “help”” | 0.6097 | 0.6050 | 1.1796 | 1.4745 | 913 | 972634 | 1.9347x |
| “help” | 0.6196 | 0.6180 | 1.1997 | 1.4996 | 913 | 972634 | 1.9362x |
| Office 212 Washington StreetSt | 0.0141 | 0.0141 | 0.3149 | 0.3936 | 1 | 1 | 22.3333x |
| https://google.com | 0.0086 | 0.0086 | 2.7748 | 3.4684 | 14 | 18 | 322.6512x |
Merge and Minimize
Very long queries where computing the merge and minimize phase dominates. Since they are so long, we will probably find a very specific token, making the intersection almost free, resulting in the difference between naive and SIMD being almost nonexistent (most of the difference is due to noise).
| Query | Simd | Naive | Meilisearch | Meilisearch (Original) | Results | Results (Meilisearch) | Performance gain |
|---|---|---|---|---|---|---|---|
| Science & Mathematics PhysicsThe hot glowing surfaces of stars emit energy in the form of electromagnetic radiation.?It is a good approximation to assume that the emissivity e is equal to 1 for these surfaces. Find the radius of the star Rigel, the bright blue star in the constellation Orion that radiates energy at a rate of 2.7 x 10^32 W and has a surface temperature of 11,000 K. Assume that the star is spherical. Use σ =… show moreFollow 3 answersAnswersRelevanceRatingNewestOldestBest Answer: Stefan-Boltzmann law states that the energy flux by radiation is proportional to the forth power of the temperature: q = ε · σ · T^4 The total energy flux at a spherical surface of Radius R is Q = q·π·R² = ε·σ·T^4·π·R² Hence the radius is R = √ ( Q / (ε·σ·T^4·π) ) = √ ( 2.7x10+32 W / (1 · 5.67x10-8W/m²K^4 · (1100K)^4 · π) ) = 3.22x10+13 mSource (s):http://en.wikipedia.org/wiki/Stefan_bolt…schmiso · 1 decade ago0 18 CommentSchmiso, you forgot a 4 in your answer. Your link even says it: L = 4pi (R^2)sigma (T^4). Using L, luminosity, as the energy in this problem, you can find the radius R by doing sqrt (L/ (4pisigma (T^4)). Hope this helps everyone.Caroline · 4 years ago4 1 Comment (Stefan-Boltzmann law) L = 4piR^2sigmaT^4 Solving for R we get: => R = (1/ (2T^2)) * sqrt (L/ (pisigma)) Plugging in your values you should get: => R = (1/ (2 (11,000K)^2)) sqrt ( (2.710^32W)/ (pi * (5.67*10^-8 W/m^2K^4))) R = 1.609 * 10^11 m? · 3 years ago0 1 CommentMaybe you would like to learn more about one of these?Want to build a free website? Interested in dating sites?Need a Home Security Safe? How to order contacts online? | 0.3440 | 0.3370 | 11.9476 | 14.9344 | 1 | 1 | 34.7314x |
| “Science News from research organizationsCancer Statistics 2014: Death rates continue to dropDate: January 7, 2014Source: American Cancer SocietySummary: An American Cancer Society report finds steady declines in cancer death rates for the past two decades add up to a 20 percent drop in the overall risk of dying from cancer over that time period. Progress has been most rapid for middle-aged black men. Nevertheless, black men still have the highest cancer incidence and death rates among all ethnicities in the US.Share:FULL STORYThe American Cancer Society finds steady declines in cancer death rates for the past two decades add up to a 20 percent drop in the overall risk of dying from cancer over that time period. Progress has been most rapid for middle-aged black men, among whom death rates have declined by approximately 50 percent.Credit: © mybaitshop / FotoliaThe annual cancer statistics report from the American Cancer Society finds steady declines in cancer death rates for the past two decades add up to a 20 percent drop in the overall risk of dying from cancer over that time period. The report, Cancer Statistics 2014, finds progress has been most rapid for middle-aged black men, among whom death rates have declined by approximately 50 percent. Despite this substantial progress, black men continue to have the highest cancer incidence and death rates among all ethnicities in the U.S.-about double those of Asian Americans, who have the lowest rates.Each year, the American Cancer Society estimates the numbers of new cancer cases and deaths expected in the United States in the current year and compiles the most recent data on cancer incidence, mortality, and survival based on incidence data from the National Cancer Institute and the Centers for Disease Control and Prevention, and mortality data from the National Center for Health Statistics. The data are disseminated in two reports, Cancer Statistics, published in CA: A Cancer Journal for Clinicians, and its companion article, Cancer Facts & Figures.This year’s report estimates there will be 1,665,540 new cancer cases and 585,720 cancer deaths in the United States in 2014. Among men, prostate, lung, and colon cancer will account for about half of all newly diagnosed cancers, with prostate cancer alone accounting for about one in four cases. Among women, the three most common cancers in 2014 will be breast, lung, and colon, which together will account for half of all cases. Breast cancer alone is expected to account for 29% of all new cancers among women.The estimated 585,720 deaths from cancer in 2014 correspond to about 1,600 deaths per day. Lung, colon, prostate, and breast cancers continue to be the most common causes of cancer death, accounting for almost half of the total cancer deaths among men and women. Just over one in four cancer deaths is due to lung cancer.During the most recent five years for which there are data (2006-2010), cancer incidence rates declined slightly in men (by 0.6% per year) and were stable in women, while cancer death rates decreased by 1.8% per year in men and by 1.4% per year in women. The combined cancer death rate has been continuously declining for two decades, from a peak of 215.1 per 100,000 in 1991 to 171.8 per 100,000 in 2010. This 20 percent decline translates to the avoidance of approximately 1,340,400 cancer deaths (952,700 among men and 387,700 among women) during this time period.The magnitude of the decline in cancer death rates from 1991 to 2010 varies substantially by age, race, and sex, ranging from no decline among white women aged 80 years and older to a 55% decline among black men aged 40 years to 49 years. Notably, black men experienced the largest drop within every 10-year age group.”“The progress we are seeing is good, even remarkable, but we can and must do even better,”” said John R. Seffrin, PhD, chief executive officer of the American Cancer Society. ““The halving of the risk of cancer death among middle aged black men in just two decades is extraordinary, but it is immediately tempered by the knowledge that death rates are still higher among black men than white men for nearly every major cancer and for all cancers combined.”“Story Source:Materials provided by American Cancer Society. Original written by Stacy Simon. Note: Content may be edited for style and length.Journal Reference:Rebecca Siegel, Jiemin Ma, Zhaohui Zou, Ahmedin Jemal. Cancer Statistics, 2014. CA: A Cancer Journal for Clinicians, 2014; DOI: 10.3322/caac.21208Cite This Page:MLA APA ChicagoAmerican Cancer Society. ““Cancer Statistics 2014: Death rates continue to drop.”” ScienceDaily. ScienceDaily, 7 January 2014. <www.sciencedaily.com/releases/2014/01/140107102634.htm>.RELATED TOPICSHealth & MedicineBreast CancerColon CancerMen’s HealthLung CancerProstate CancerCancerPancreatic CancerBrain TumoradvertisementRELATED TERMSColorectal cancerOvarian cancerCervical cancerStomach cancerBreast cancerProstate cancerCancerHepatocellular carcinomaRELATED STORIESBreast Cancer Incidence, Death Rates Rising in Some Economically Transitioning CountriesSep. 10, 2015 — A new study finds breast cancer incidence and death rates are increasing in several low and middle income countries, even as death rates have declined in most high income countries, despite … read moreRacial Differences in Male Breast Cancer OutcomesMay 4, 2015 — While black and white men under age 65 diagnosed with early-stage breast cancer received similar treatment, blacks had a 76 percent higher risk of death than whites, research shows. Male breast … read moreMore Than 1.5 Million Cancer Deaths Averted During 2 Decades of Dropping MortalityDec. 31, 2014 — The American Cancer Society’s annual cancer statistics report finds that a 22 percent drop in cancer mortality over two decades led to the avoidance of more than 1.5 million cancer deaths that … read moreColon Cancer Incidence Rates Decreasing Steeply in Older Americans, Study ShowsMar. 17, 2014 — Colon cancer incidence rates have dropped 30 percent in the US in the last 10 years among adults 50 and older due to the widespread uptake of colonoscopy, with the largest decrease in people over age … read moreFROM AROUND THE WEBBelow are relevant articles that may interest you. ScienceDaily shares links and proceeds with scholarly publications in the TrendMD network.” | 1.2170 | 1.1574 | 46.1473 | 57.6841 | 1 | 299990 | 37.9189x |
| (Image credit: Emma Christensen)Open SlideshowThe perfect baked potato is crispy on the outside and pillowy in the middle. Cracked open and still steaming, it’s ready to receive anything from a sprinkle of cheese to last night’s stew. Here’s how to make one.Baking a potato in the oven does require a little more time than zapping it in the microwave, but it’s mostly hands-off time. You can walk in the door, throw a few potatoes in oven while it’s still warming up, and carry on with your after-work routine until they’re ready to eat. Just don’t forget to set a timer! (Image credit: Kitchn)Russets are the best for baking like this. The skins are thicker and the starchy interior has a sweet flavor and fluffy texture when baked. Russets are also typically fairly large. One of them per person makes a good side dish or meal on its own.Russets are the best for baking like this. The skins are thicker and the starchy interior has a sweet flavor and fluffy texture when baked.How To Bake a PotatoWhat You NeedIngredients1russet potato per personOlive oilSaltPepperEquipmentA forkA baking sheet covered in foilInstructionsHeat the oven to 425°F: Turn on the oven while you’re preparing the potatoes.Scrub the potatoes clean: Scrub the potatoes thoroughly under running water and pat them dry. You don’t have to remove the eyes, but trim away any blemishes with a paring knife.Rub the potatoes with olive oil: Rub the potatoes all over with a little olive oil. It’s easiest to use your hands, but a pastry brush also works fine.Sprinkle the potatoes with salt and pepper: Generously sprinkle the potatoes on all sides with salt and pepper.Prick all over with a fork: Prick the potatoes in a few places with the tines of a fork. This allows steam to escape from the baking potato.Bake the potatoes: You can bake the potatoes directly on the oven rack, or you can place them a few inches apart on a foil-lined baking sheet. Bake the potatoes for 50 to 60 minutes. Flip them over every 20 minutes or so and check them for doneness by piercing them with a fork. Potatoes are done when the skins are dry and the insides feel completely soft when pierced.Recipe NotesTo cut down the baking time, microwave the potatoes for 3 to 4 minutes in the microwave before baking.For softer skins, wrap the potatoes in foil before baking.Print RecipeShow Nutrition | 0.4801 | 0.4709 | 13.6963 | 17.1204 | 2 | 2 | 28.5280x |
Single Token
Queries where during the merge and minimize phases got combined into a single one. Here, we mainly bottleneck on getting the document IDs out of the Roaringish Packed. Since we don’t even compute an intersection, the difference between naive and SIMD is very close (most of the difference is due to noise).
| Query | Simd | Naive | Meilisearch | Meilisearch (Original) | Results | Results (Meilisearch) | Performance gain |
|---|---|---|---|---|---|---|---|
| what is | 0.1388 | 0.1406 | 2.0680 | 2.5850 | 425323 | 496590 | 14.8991x |
| what is the | 0.0411 | 0.0508 | 2.1396 | 2.6745 | 150270 | 245645 | 52.0584x |
| the name | 0.0789 | 0.0790 | 3.0809 | 3.8511 | 208130 | 212102 | 39.0482x |
| name the | 0.0030 | 0.0031 | 1.2899 | 1.6124 | 10506 | 17944 | 429.9667x |
| your house | 0.0056 | 0.0063 | 3.5441 | 4.4301 | 22953 | 23907 | 632.8750x |
| and the | 0.9163 | 0.9169 | 1.6157 | 2.0196 | 1415088 | 1419321 | 1.7633x |
| you can go | 0.0041 | 0.0045 | 6.6274 | 8.2843 | 16947 | 20754 | 1616.4390x |
| do not | 0.1826 | 0.1826 | 1.4025 | 1.7531 | 534453 | 541560 | 7.6807x |
| $3,000 | 0.0037 | 0.0039 | 1.6308 | 2.0385 | 12494 | 13006 | 440.7568x |
Final thoughts
We beat Meilisearch in 49/53 queries, achieving performance increases ranging from 1.5x to 1600x. I’m more than happy with the final results.
With one or two new optimization ideas, we could probably beat Meilisearch in all 53 queries, but at this point, I’m kind of tired of the project and out of ideas.
I’m also very happy with the performance of the SIMD algorithm compared to the naive version.
I hope you enjoyed the ride. <3